Home / Blog
Axipro Resource Hub
Latest Articles

One in five organizations has already suffered a breach traced back to shadow AI. Meanwhile, 63% of breached organizations either have no AI governance policy at all or are still drafting one. Below is a complete, copy-ready shadow AI policy template with twelve sections, plus guidance on adapting it for your company size, your industry, and the regulatory frameworks you answer to. The template assumes one hard truth up front: your employees are already using unapproved AI tools. A policy that pretends adoption hasn’t started yet fails on day one, so this one starts from the assumption that it has. What Is a Shadow AI Policy? A shadow AI policy is a formal document that defines how your organization discovers, evaluates, approves, and governs AI tools that employees adopt outside official IT channels. The term borrows from shadow IT, the older problem of unsanctioned software and hardware, but the AI version carries sharper risks: data pasted into a public model may be retained, used for training, or exposed in ways the organization can’t reverse. The policy does three jobs: it separates approved use from unapproved use, gives employees a fast and visible way to request new tools so the sanctioned route beats the workaround, and spells out what happens when someone crosses the line, including how the organization detects it and responds. Shadow AI Policy vs. General AI Acceptable Use Policy Many organizations already have an AI acceptable use policy (AUP) and assume it covers shadow AI. It usually doesn’t. An AUP tells employees how to behave inside approved tools. A shadow AI policy governs the tools themselves: which ones exist in your environment, which ones are allowed, and what happens with the rest. You need both. The AUP handles conduct; the shadow AI policy handles inventory and control. If you only have room for one document, fold the AUP’s data-handling rules into Section 6 of the template below. Let Axipro help you build a business continuity plan that’s practical, compliant, and audit-ready. Strengthen Your Business Continuity Strategy Schedule A Consultation The Shadow AI Policy Template (Download Link and Copy-Ready Sections) We’ve created a compliance safe template for Shadow AI Policy, use the link below to create a copy and customize for your company: Download The Shadow AI Policy Template → Copy the sections below into your policy management system and replace the bracketed placeholders. The language is plain on purpose. Legalese gets skimmed. Section 1: Purpose and Scope This policy governs the acquisition, approval, and use of artificial intelligence tools, features, and services at [Company]. It applies to all employees, contractors, interns, and third parties with access to [Company] systems or data. It covers standalone AI applications, AI features embedded in existing software, browser extensions, AI agents, APIs, and personal AI accounts used for work purposes, on both corporate and personal devices. The purpose of this policy is to enable productive AI use while protecting [Company] data, customers, and legal obligations. This policy does not prohibit AI. It prohibits ungoverned AI. That last sentence matters. Employees read the purpose statement first, and it decides whether they see the policy as an enabler or a blocker. Section 2: Definitions and Terminology Shadow AI: any AI tool, feature, agent, or service used for work purposes without formal approval under this policy. Approved AI Tool: an AI tool listed in the Approved AI Tools Registry (Section 4) and used under a [Company]-managed account. Personal AI Account: an account on any AI service registered to a personal email address or paid for personally. AI Feature: AI functionality embedded within otherwise approved software (e.g., an AI assistant added to a project management tool), which requires separate evaluation. Sensitive Data: data classified as [Confidential] or [Restricted] under [Company]‘s data classification policy, including the prohibited data classes in Section 6. Define “AI feature” explicitly. Vendors now ship AI additions into already-approved SaaS products every month, and without this definition, those features inherit approval they never earned. Section 3: Roles and Responsibilities The CISO (or designated security lead) owns this policy, maintains the Approved AI Tools Registry, and runs the approval workflow. Department heads ensure their teams know the policy and surface tool requests rather than suppressing them. Legal and Compliance review tools that touch regulated data or fall under the EU AI Act, GDPR, HIPAA, or client contractual restrictions. IT operates detection and monitoring controls (Section 9). Every employee is responsible for using only approved tools for work, reporting unapproved AI use they discover, and requesting new tools through the workflow in Section 7 rather than adopting them directly. Insider Note: In organizations under roughly 200 people, the “CISO” in this section is often the same overworked IT lead who manages laptops. Name a real person, not a title that doesn’t exist yet. A policy that assigns duties to a phantom role is unenforceable, and auditors notice. Section 4: Approved AI Tools Registry [Company] maintains a registry of approved AI tools at [location/URL]. For each tool, the registry records: tool name and vendor, approved use cases, prohibited use cases, permitted data classes, account type (enterprise/team/individual), data retention and training settings, risk tier (Section 5), approval date, and next review date. Only tools listed in the registry may be used for work. Tools not listed are unapproved by default. The registry is reviewed [quarterly]. Keep the registry somewhere employees actually look, such as your intranet homepage or IT help center, not buried in a GRC platform they can’t access. An invisible registry recreates the problem the policy exists to fix. Section 5: Risk Tier Classification (Low, Medium, High) Each tool in the registry is assigned a risk tier. Low: the tool processes only public or internal non-sensitive data, runs under an enterprise agreement with training opt-out, and produces output that a human reviews before use. Approval by IT Security alone. Medium: the tool processes internal business data or connects to [Company] systems via API or integration. Approval by IT Security plus the data owner. High: the

Legacy threat modeling frameworks such as STRIDE were designed for software that behaves the same way over and over again. Agentic AI does no such thing. It can rewrite its own plan mid-task, call external tools, negotiate with other agents, and produce a different output from identical input. MAESTRO exists because none of the legacy threat modeling frameworks were built to handle that. MAESTRO stands for Multi-Agent Environment, Security, Threat, Risk, and Outcome. It is a seven-layer threat modeling framework created specifically for agentic AI systems, and it has become the closest thing the industry has to a standard method for reasoning about agent security. Understanding MAESTRO in the Context of Agentic AI What MAESTRO Stands For Each word in the acronym carries meaning. Multi-Agent Environment signals that the framework models entire ecosystems of interacting agents, not a single model behind an API. Security, Threat, Risk covers the core discipline: identifying attack surfaces, cataloging threats, and assessing likelihood and impact. Outcome is the part most frameworks skip. MAESTRO asks what an attack actually produces in the real world, because an autonomous agent with tool access turns a compromised prompt into a compromised action. The Origin of MAESTRO (Cloud Security Alliance) The Cloud Security Alliance published MAESTRO in February 2025. Its creator is Ken Huang, Co-Chair of the CSA AI Safety Working Groups and CEO of DistributedApps.ai. The CSA has since applied the framework publicly to real systems, including OpenAI’s Responses API and Google’s A2A protocol, which gives practitioners worked examples rather than just theory. The framework is openly published, and the CSA maintains an official companion tool, the MAESTRO Threat Analyzer, on GitHub. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule Free Assessment Why Traditional Frameworks Fall Short for Agentic AI STRIDE, PASTA, LINDDUN, and OCTAVE all share a founding assumption: the system under analysis follows predictable logic with clearly defined boundaries. You draw the data flow diagram, mark the trust boundaries, and enumerate threats against components that behave deterministically. Agentic AI breaks every part of that assumption. Unique Security Challenges of Autonomous Agents Agents introduce three properties that legacy models cannot express. Non-determinism means the same input can produce different behavior, so you cannot enumerate execution paths in advance. Autonomy means the agent makes decisions and takes actions without a human approving each step, which collapses the usual assumption that a person sits between intent and execution. And in multi-agent systems there is often no stable trust boundary: agents delegate to other agents, consume tool outputs from external servers via protocols like the Model Context Protocol (MCP), and update their own memory and goals at runtime. The Gap Between Legacy Frameworks and Agent-Based Systems The practical consequence is coverage gaps. STRIDE has no category for goal manipulation, where an attacker gradually steers what an agent is trying to achieve. PASTA assumes attacker objectives and data flows are fixed, which fails for systems that learn and adapt during operation. LINDDUN addresses privacy but says nothing about agent collusion or memory poisoning. A threat model built purely on these frameworks will pass review and still miss the attacks that matter most in an agentic deployment. How MAESTRO Addresses Agentic-Specific Risks MAESTRO does not discard the older frameworks. It extends them with a layered reference architecture, an AI-specific threat catalog for each layer, and, critically, explicit analysis of how threats propagate between layers. That cross-layer lens is the framework’s real contribution, because most serious agentic incidents are chains: poisoned data influences a model, the model misleads an agent, and the agent takes an unauthorized action three layers away from where the attack started. The Seven Layers of the MAESTRO Framework MAESTRO decomposes any agentic system into seven layers, each with its own threat landscape. Layer 1: Foundation Models The core LLMs or other models the agents reason with. Threats here include adversarial examples, model extraction, backdoored weights, and jailbreaks that bypass safety training. If the model is a third-party API, supply chain risk lives at this layer too. Layer 2: Data Operations Everything the agent ingests, stores, and retrieves: training data, RAG pipelines, vector databases, and agent memory. Data poisoning and memory tampering are the signature threats at this layer, and they are especially dangerous because a poisoned memory persists across sessions and keeps shaping future decisions long after the initial attack. Layer 3: Agent Frameworks The orchestration software that turns a model into an agent: LangChain, CrewAI, AutoGen, custom planners, and tool-calling logic. Threats include prompt injection through tool outputs, insecure tool definitions, and manipulation of the planning loop itself. Layer 4: Deployment Infrastructure The servers, containers, and cloud services the agents run on. The CSA’s threat catalog here reads like traditional cloud security with an agentic twist: compromised container images carrying malicious agent code, Kubernetes orchestration attacks, denial of service against agent runtimes, and tampering with Infrastructure-as-Code templates that provision agent resources. Layer 5: Evaluation and Observability The systems that monitor, evaluate, and debug agent behavior. This layer is often forgotten, and attackers know it. The CSA specifically flags poisoning observability data: manipulating the telemetry fed to monitoring systems so that incidents stay hidden from security teams while malicious activity continues. Layer 6: Security and Compliance MAESTRO treats this as a vertical layer that cuts across all others: identity and access management, guardrails, policy enforcement, and compliance controls. Threats include permission escalation, guardrail bypass, and compromise of the security agents themselves in architectures where AI enforces policy on other AI. Layer 7: Agent Ecosystem The environment where agents interact with users, other agents, and marketplaces. This is where the genuinely novel threats live: agent impersonation, misleading agent capability cards, tool squatting, and collusion between agents to achieve outcomes no single agent was authorized to pursue. Insider Note: In real assessments, Layers 5 and 6 expose the maturity gap fastest. Most teams’ shipping agents can describe their model and their orchestration framework in detail, then
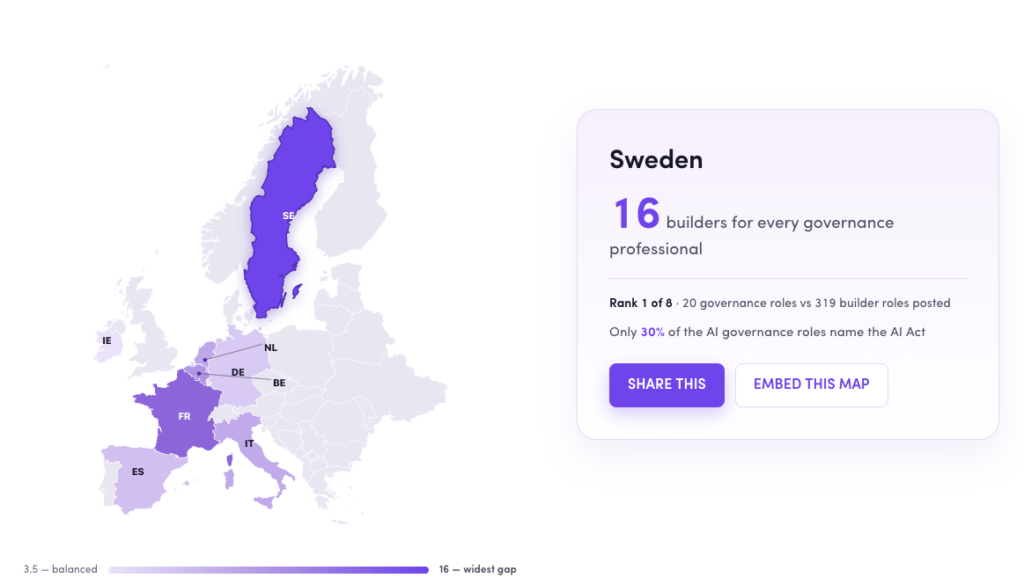
AXIPRO STUDY New Study: Europe is hiring AI builders faster than AI governance professionals Axipro analyzed 3,519 AI-related job postings across eight EU countries. For every professional hired to keep AI lawful, safe and accountable, nearly seven were hired to build more of it, and the gap is widest exactly where you’d least expect. Take EU AI ACT READINESS QUIZZ 16 AI Builders : 1 AI Governors Sweden — Europe’s widest AI governance gap 3,519 Job Postings Analyzed 8 EU Countries 2 Role Categories: Builders vs Governors July 2026 Date of Job Postings Analyzed The findings Finding 1: Sweden hires 16 AI builders for every 1 person to govern them Throughout our data-set we found the same pattern across all eight countries: the more a nation hires to build AI, the less it hires to govern it. France runs eleven builders to every governor. Even Ireland, the most balanced in Europe, looks responsible mainly because the US tech giants headquartered there import global-governance discipline under overlapping DORA and AI Act pressure. 3.5→16 builders hired per governor, Europe’s most balanced country to its least. Ireland 3.5 Germany 5.7 Spain 6.0 Italy 7.1 Netherlands 7.2 Belgium 7.9 France 11.4 Sweden 16:1 0 4 8 12 16 Builders hired per AI governor Source: Axipro, 2026 Sweden has one of the strongest engineering cultures in Europe. It also carries the widest governance gap we measured: sixteen AI builders hired for every person hired to govern them. France sits close behind at eleven to one. The most balanced country, Ireland at 3.5 to one, looks responsible for a reason that has little to do with virtue. The US tech giants headquartered in Dublin import global governance discipline, and they do it under the combined weight of the AI Act and DORA, the EU financial-sector resilience regime in force since January 2025. Engineering strength does nothing to close a governance gap, and it may widen it. A country that ships AI faster produces more systems that fall under the Act’s scope and, on this evidence, fewer people positioned to document, monitor, and defend them. Being good at building AI offers no protection against governing it badly. The countries most confident in their technical talent are running the largest deficit against the law. Explore AI governance hiring by country Click any country to see how many AI builders it hires for every governance professional, and where it ranks against the rest of Europe. Germany — 5.7 builders per governorDE France — 11.4 builders per governorFR Spain — 6.0 builders per governorES Italy — 7.1 builders per governorIT Netherlands — 7.2 builders per governorNL Belgium — 7.9 builders per governorBE Ireland — 3.5 builders per governorIE Sweden — 16 builders per governorSE 3.5 — balanced 16 — widest gap Source: Axipro, 2026 Sweden 16builders for every governance professional Rank 1 of 8 · 20 governance roles vs 319 builder roles posted Only 30% of the AI governance roles name the AI Act Share this Embed this map Copy & paste — links back to Axipro Copy embed code Branded, one paste, backlink included. × Share this country insight Share this AI governance gap X / Twitter LinkedIn Facebook WhatsApp Bluesky Email Copy link Choose a platform or copy the link. A view of the same country-level dataset behind the interactive map: governance roles, builder roles, builder-to-governance ratio, and the share of governance postings that name the EU AI Act. AI governance jobs Europe statistics by country: governance roles, builder roles, builder-to-governance ratio and AI Act mention percentage. Country Governance roles Builder roles Builder-to-governance ratio AI Act mention % Sweden 20 319 16.0:1 30.0% France 39 443 11.4:1 38.5% Belgium 38 299 7.9:1 39.5% Netherlands 61 439 7.2:1 31.1% Italy 40 284 7.1:1 45.0% Spain 64 384 6.0:1 28.1% Germany 88 501 5.7:1 27.3% Ireland 96 335 3.5:1 14.6% Source: Axipro analysis of AI builder, governance and compliance job postings across eight European countries. “AI Act mention %” is the share of governance postings that explicitly name the EU AI Act. Finding 2: The law nobody names. Most AI governance jobs still do not mention the EU AI Act Europe spent years drafting the AI Act. It cleared the European Parliament, survived the Digital Omnibus revisions, and now carries penalties that reach €35 million or 7% of global turnover for the most serious breaches, a ceiling that makes GDPR fines look modest. Yet fewer than three in ten of the governance roles created to handle it actually name the law in the job description. Among builder roles, the figure collapses to one in twenty-five. More than 7 in 10 Governance job descriptions do not mention the EU AI Act. This number rises to 9 in 10 for all AI job descriptions. Despite hiring for governance, risk, privacy, and compliance roles, most employers are not yet translating the EU AI Act into explicit job requirements. That disconnect should stop you. The people being hired to make Europe compliant are, for the most part, not being hired against the Act by name. They are titled around adjacent ideas: risk, ethics, model validation, data protection. Some of that work will map onto the Act’s requirements. Much of it will not, because a role written without the regulation in view rarely produces the conformity assessments, technical documentation, and human-oversight structures the Act specifically demands. Readiness is even thinner than the headcount suggests. Simply counting governance hires overstates how many people are actually working the law. What job descriptions actually name The EU AI Act is visible in governance roles — but still absent from most job ads. Across the laws and frameworks most relevant to AI governance hiring, the EU AI Act appears in fewer than three in ten governance postings, and only 4% of builder postings. Law or framework Governance roles naming it Builder roles naming it All roles naming it Governance mentions EU AI Act 28.5% 4.0% 7.6% 127 GDPR 26.9% 5.7% 9.6% 120 ISO 27001 11.4% 1.3% 2.8% 51

78% of organizations have no formal policies for creating or removing AI agent identities, according to a 2026 report from the Cloud Security Alliance and Oasis Security. The same research found that 92% are not confident that their legacy identity and access management tools can handle the risks agents introduce. Those two numbers describe the problem in full: enterprises are deploying autonomous software that reads email, queries databases, and triggers actions across production systems, and most of them cannot say who authorized it, what it can touch, or how they would prove any of that to an auditor. This is not a future problem. Agents are already operating inside regulated environments governed by the GDPR, HIPAA, SOX, and the EU AI Act. Every access decision an agent makes is a compliance event, whether or not anyone is logging it. This article covers what regulators actually expect, where traditional IAM falls short, and how to build an access framework for AI agents that survives an audit. Understanding the Compliance Landscape for AI Agents Key Regulations Impacting AI Agent Access No regulation says “AI agent” and then hands you a checklist. Instead, agents inherit obligations from every framework that governs the data and systems they touch. Under the GDPR, an agent processing personal data triggers the full set of principles in Article 5: lawfulness, purpose limitation, data minimization, and accountability. If an agent makes decisions that produce legal or similarly significant effects on individuals, Article 22 restrictions on automated decision-making apply as well. HIPAA requires covered entities to implement access controls, audit controls, and integrity protections for electronic protected health information under the Security Rule, and an agent with access to ePHI is subject to the same technical safeguards as a human workforce member. SOX demands that access to financial reporting systems be controlled, segregated, and reviewable, which becomes genuinely difficult when an autonomous agent can touch the general ledger. The EU AI Act adds an AI-specific layer, and its timeline is widely misunderstood. Following the Digital Omnibus agreement, obligations for standalone high-risk systems under Annex III were deferred to December 2, 2027. But the Article 50 transparency obligations still apply from August 2, 2026, meaning agents that interact with people in the EU must disclose their artificial nature on the original schedule. Treating the Omnibus as a blanket delay is one of the most common compliance mistakes being made right now. Important: The Digital Omnibus deferred the high-risk regime, not the whole Act. If an AI agent interacts with users in the EU, the August 2, 2026, transparency requirements were not moved, and the AI Office’s enforcement powers go live on the same date. Do not stand down 2026 workstreams based on headlines about the 2027 deferral. How AI Agents Create New Compliance Risks Agents break the assumptions most compliance programs are built on. A human user requests access, receives a role, and behaves within a predictable envelope. An agent reasons about its own goals, chains tool calls across systems, and can attempt actions its designers never anticipated. It operates at machine speed and machine volume, so a misconfigured permission produces thousands of non-compliant data touches before anyone notices. And because agents frequently run on shared service accounts or borrowed OAuth tokens, attribution collapses: the audit log says the CRM was queried, but not by whom, for what purpose, or under whose authority. The Gap Between Traditional IAM Compliance and Agentic AI Traditional IAM assumes identities are stable, access needs are predictable, and behavior maps to a job description. None of that holds for agents. A 2026 Cloud Security Alliance survey found that 68% of organizations cannot reliably distinguish AI agent activity from human activity in their logs. For a compliance function, that is disqualifying. If you cannot separate agent actions from human actions, you cannot certify access, demonstrate segregation of duties, or respond to a data subject access request with confidence. Core Compliance Requirements for AI Agent Access Auditability and Traceability of Agent Actions Every major framework converges on the same demand: show your work. For agents, a login timestamp is not enough. A defensible audit trail captures the full chain of custody for each action: which agent acted, which human or process delegated the authority, which tool or API was invoked, which data was accessed, and what the outcome was. Gartner’s 2026 Market Guide for what it calls “guardian agents” describes exactly this pattern of recording agent-to-tool-to-target chains for compliance reporting and incident response. Data Protection and Privacy Obligations Agents must operate inside the same data protection perimeter as everything else. That means Data Loss Prevention (DLP) controls apply to agent outputs, not just human uploads. It means an agent’s access to personal data needs a lawful basis, documented before deployment, not reverse-engineered after. And it means retention rules follow the data into whatever context window, vector store, or scratchpad the agent moves it into. Separation of Duties in Autonomous Systems Separation of duties exists so that no single actor can both commit and conceal an error or a fraud. A single agent granted permissions across procurement, approval, and payment reconstitutes exactly the toxic combination SOX controls were designed to prevent, except now it executes at machine speed. The control translates directly: no agent should hold permission sets that a human in the same process would be prohibited from combining, and multi-agent workflows need the same conflict analysis as human role assignments. Consent, Purpose Limitation, and Data Minimization Purpose limitation is the principle that agents most naturally violate. An agent given broad access “to be helpful” will use data collected for one purpose to accomplish another, because nothing in its architecture knows the difference. Compliance-ready agent access means scoping data access to the declared purpose of the task and enforcing that scope technically rather than hoping the system prompt holds. Insider Note: In practice, the purpose limitation failures we see are rarely dramatic. They look like a support agent enriching a ticket with data pulled from the sales

SOC 2 is not a certification, and no auditor will ever hand you a SOC 2 certificate. What you receive at the end of the audit is an attestation report: a detailed document, often 60 to 100 pages long, in which a licensed CPA firm expresses a professional opinion on your controls. That distinction sounds like pedantry until a prospect’s security team asks to see your “certificate” and you have nothing that looks like one. This article explains exactly what a SOC 2 report is, what it contains, how it differs from an ISO 27001 certificate, and how to talk about your SOC 2 status without misrepresenting it. Is SOC 2 a Certification or a Report? The Common Misconception About “SOC 2 Certification” Search volume tells the story: far more people look for “SOC 2 certification” than for “SOC 2 attestation,” and sales teams, procurement questionnaires, and even some auditors use the certification shorthand daily. The misconception is understandable. Every other major framework in the compliance stack, from ISO 27001 to PCI DSS, ends in something that looks like a pass. SOC 2 does not work that way, and treating it as if it does leads to awkward conversations during vendor due diligence. Why SOC 2 Is Technically an Attestation, Not a Certification A certification is a binary judgment issued by an accredited body: you meet the standard, or you do not. SOC 2 sits under the AICPA’s attestation standards, primarily SSAE 18 and its later amendments (SSAE 21 updated the relevant examination sections), specifically AT-C section 105 and AT-C section 205. Under those standards, an independent service auditor examines your controls and reports an opinion on them. Nobody “passes.” The auditor attests to what they found, in writing, with evidence. The output is a report, and the report is the entire deliverable. Understanding the SOC 2 Attestation Model What Is an Attestation Engagement? An attestation engagement is a formal examination in which a practitioner evaluates subject matter prepared by another party against defined criteria, then issues a written conclusion. In SOC 2, the subject matter is your system and its controls, the criteria are the AICPA’s Trust Services Criteria (Security, Availability, Processing Integrity, Confidentiality, and Privacy), and the party preparing the subject matter is you, the service organization. Security is the only mandatory category; the other four are scoped in based on your service commitments. The Role of the AICPA and Licensed CPA Firms The AICPA (American Institute of Certified Public Accountants) owns the SOC framework and the attestation standards behind it, but it does not perform audits and does not issue anything to your company. Only a licensed CPA firm can conduct a SOC 2 examination and sign the resulting opinion. That licensing requirement is the quality mechanism: the firm’s professional liability, independence rules, and peer review obligations stand behind the report. In practice, this means the assurance you get is only as strong as the auditor’s reputation and independence posture, which is why enterprise buyers often look at who signed the report almost as carefully as they look at what it says. How Attestation Differs from Certification and Accreditation The three terms describe different assurance models. Certification means an accredited certification body confirms conformity with a standard and issues a certificate, as happens with ISO 27001. Accreditation is one level up: it is the process by which national bodies, such as those coordinated through the International Accreditation Forum, authorize those certification bodies to certify in the first place. Attestation involves no certificate and no accreditation chain. A CPA firm examines evidence and expresses an opinion under professional standards. The credibility comes from the auditor’s license and independence, not from a badge. What You Actually Receive After a SOC 2 Audit The SOC 2 Attestation Report Explained The deliverable is a confidential, restricted-use document addressed to your management and intended for your customers, their auditors, and other informed parties. It is dense by design. A prospect’s risk team reads it to understand what your system does, which controls you operate, how the auditor tested them, and what the auditor found. It replaces a certificate with something far more useful: evidence. Key Components of the Final Report Independent service auditor’s opinion. The first section, usually two to three pages, states the auditor’s formal conclusion on whether your system description is fairly presented and whether your controls were suitably designed (and, for Type 2, operating effectively). This is the section report readers check first. Management’s assertion. A signed statement in which your leadership formally asserts that the system description is accurate and that controls meet the applicable criteria. SSAE 18 made this management assertion a mandatory element, which means responsibility for the description sits with you, not the auditor. System description. The longest narrative section was prepared by management against the AICPA’s SOC 2 description criteria. It covers the services provided, infrastructure, software, people, data, processes, subservice organizations, and complementary user entity controls. Trust Services Criteria and controls tested. A mapping of each in-scope criterion to the specific controls you operate. This is where scoping decisions become visible: a report covering Security only looks very different from one covering all five categories. Results of testing. For Type 2 reports, a control-by-control table showing the tests the auditor performed and the results, including any exceptions. Sophisticated readers spend most of their time here, because exceptions and the auditor’s response to them reveal more than the opinion page does. What a SOC 2 Report Is NOT (No Certificate, No Logo, No Pass/Fail Badge) There is no official SOC 2 certificate, no numbered credential, and no register of “certified” companies you can be listed in. The AICPA licenses a standard SOC logo that service organizations may display for a limited time after report issuance, but the logo confirms only that an examination took place. It says nothing about the opinion inside. Anyone selling you a “SOC 2 certificate” as a standalone artifact is selling something the framework does not produce. Important: If

The full SIG content library contains 1,936 questions. SIG Lite asks 128 of them. That difference is the entire point: most vendor relationships do not justify a multi-week questionnaire exchange, and SIG Lite exists so risk teams can run standardized due diligence on lower-risk vendors without burning analyst hours or vendor goodwill. What Is SIG Lite? SIG Lite is the streamlined version of the Standardized Information Gathering (SIG) questionnaire, the most widely used third-party risk assessment instrument in the industry. It condenses the full SIG question set into a short, high-level assessment of a vendor’s information security, privacy, and resilience controls. It is a self-assessment, not an audit: the vendor answers, the assessor evaluates, and the completed questionnaire becomes evidence of due diligence in a third-party risk management (TPRM) program. Purpose of the SIG Lite Questionnaire The purpose is speed with consistency. SIG Lite gives an outsourcing organization a broad understanding of a third party’s internal control environment using a standardized question set, so answers are comparable across an entire vendor portfolio. It works either as a complete assessment for low-risk vendors or as a preliminary screen that decides whether a deeper review is warranted. Because every vendor answers the same questions, risk teams can rank, tier, and triage instead of interpreting fifty differently formatted responses. Who Created and Maintains SIG Lite? SIG Lite is owned and maintained by Shared Assessments, a member-driven standards organization formed in 2005 when the Big Four accounting firms and six global banks set out to fix the inefficiency of every company writing its own vendor questionnaire. The SIG is developed through a formal governance process that draws on practitioner feedback and tracks evolving regulations and standards, which is a large part of why it has held its position as the de facto industry template. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule Free Assessment What’s Included in the SIG Lite Questionnaire? Number of Questions and Structure The 2025 release of SIG Lite contains 128 questions. The exact count shifts slightly with each annual update (recent versions have ranged from roughly 126 to 133), so always confirm the version you are working with. Questions are predominantly yes/no with room for comments and references to supporting evidence, and each question maps back to the SIG content library and to external frameworks. SIG Lite ships as a single-worksheet questionnaire, which keeps completion and review manageable. Risk Domains Covered in SIG Lite SIG Lite draws its questions from the same 21 risk domains that structure the entire SIG, grouped into four control areas: Governance and Risk Management, Information Protection, IT Operations and Business Resilience, and Security Incident and Threat Management. In practice, that means high-level coverage of access control, information security policy, data privacy, cloud security, business continuity, incident response, supply chain risk, human resources security, compliance management, and ESG, among others. The breadth is the same as SIG Core; the depth per domain is what gets trimmed. Format and Delivery (Spreadsheet and Toolkit) Historically, the SIG has been delivered as an Excel workbook generated by the SIG Manager, the macro-driven engine inside the SIG Questionnaire Toolkit that lets assessors scope, generate, store, and compare questionnaires. That is changing. In March 2026, Shared Assessments launched SIG EV (Evolution), a browser-based platform that moves questionnaire creation, distribution, comparison, and grading to the cloud while preserving the same content and methodology. Vendors can still respond in Excel, and assessors can upload completed files, so the transition does not break existing workflows. Worth Knowing: SIG Questions & Permissions SIG questions cannot be edited without written permission from Shared Assessments, but assessors can add up to 100 custom questions to a scoped questionnaire. That is usually enough headroom to cover industry-specific requirements without abandoning the standard. When Should You Use SIG Lite? Ideal Vendor Risk Scenarios SIG Lite fits three situations well. First, vendors with no access to sensitive data or critical systems, where a full assessment would be disproportionate. Second, large vendor portfolios, where sending 600-plus questions to every supplier would stall onboarding across the board. Third, early-stage evaluation, where you need enough signal to decide whether a relationship is worth deeper diligence. Low-Risk vs. High-Risk Vendor Assessments The dividing line is data and criticality. A marketing tool that touches no customer records, a facilities contractor, or a niche SaaS product with read-only access to public data can all be assessed adequately with SIG Lite. A payroll processor, a cloud provider hosting production data, or any vendor storing regulated information under HIPAA, PCI DSS, GDPR, or GLBA should get SIG Core. Using Lite on a high-risk vendor is a documented gap waiting to be found in your next audit. Initial vs. In-Depth Risk Screening Many mature programs use SIG Lite as a gate rather than a destination. The Lite response feeds an initial risk score; vendors that trip defined thresholds (a missing incident response plan, no encryption at rest, no independent certification) graduate to SIG Core or a targeted domain-level assessment. This two-stage pattern keeps effort proportional to risk and gives vendors a lighter first touch. SIG Lite vs. SIG Core: Key Differences Both questionnaires come from the same content library and cover the same 21 risk domains. The differences are scope, depth, and effort. Question Count and Scope SIG Lite’s 128 questions sit at the top of the control hierarchy: does a policy exist, is a program in place, and is there independent validation? SIG Core’s 627 questions descend into how each control actually operates. Beyond both sits the full SIG Detail library of 1,936 questions, which assessors use to build custom scopes by regulation, domain, or control family. Depth of Assessment A SIG Lite answer tells you a vendor has an access control program. A SIG Core response tells you how privileged accounts are reviewed, how quickly access is revoked at termination, and how authentication is enforced across environments. If your obligation is

In 2018, a cyberattack on SingHealth exposed the records of 1.5 million patients, including the Prime Minister. The Personal Data Protection Commission (PDPC) handed down S$1 million in combined penalties, and that decision still sits on its public enforcement page today. The Personal Data Protection Act (PDPA) has sharper teeth than it did a few years ago. Since October 2022, the PDPC can impose financial penalties of up to 10% of an organisation’s annual turnover in Singapore, or S$1 million, whichever is higher. Breach notification is now mandatory. And a hard deadline is approaching: from 1 January 2027, using NRIC numbers for authentication becomes an enforcement target. A checklist is how you turn all of that into something you can actually execute against, rather than a legal document you skim once and forget. What Is the PDPA Compliance Checklist? A PDPA compliance checklist translates the law’s 11 data protection obligations into concrete, verifiable actions. The obligations themselves are principles: Consent, Purpose Limitation, Notification, Access and Correction, Accuracy, Protection, Retention Limitation, Transfer Limitation, Data Breach Notification, Accountability, and Data Portability (legislated in 2020 but not yet in force). A principle tells you what good looks like. A checklist tells you whether you have done it. The distinction matters because the PDPC does not accept good intentions as a defense. When it investigates, it looks for documented policies, a named Data Protection Officer (DPO), evidence of consent, and a breach plan that existed before the breach. The checklist is what produces that evidence trail. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule Free Assessment Who Needs to Follow the PDPA Compliance Checklist in Singapore Every private sector organisation that collects, uses, or discloses personal data in Singapore falls under the PDPA. That covers sole proprietorships, partnerships, companies, and foreign entities with Singapore operations. Headcount is irrelevant. A five-person startup carries the same obligations as a multinational, and the PDPC has shown it will penalize small and mid-sized businesses, not only household names. Physical presence is not the trigger either. If your processing touches individuals in Singapore, the Act can reach you even without a local office. Public sector agencies sit under separate legislation, but the private sector rules administered by the PDPC, which operates under the Info-communications Media Development Authority (IMDA), apply broadly. One useful carve-out: business contact information used purely for business purposes is largely exempt from the consent rules. Worth Knowing: PDPA Roles Explained The PDPA distinguishes an organisation from a data intermediary, a party that processes data on another’s behalf. Intermediaries carry a narrower but real set of duties, mainly protection and retention. If you outsource payroll, hosting, or email marketing, you are the organisation and your vendor is the intermediary, and the contract between you needs to say so explicitly. PDPA Compliance Checklist: Step-by-Step Guide The 15 steps below move roughly in the order you should tackle them, from governance foundations through operational controls to ongoing assurance. Treat them as a sequence, not a menu. Step 1: Appoint a Data Protection Officer (DPO) The PDPA requires every organisation to designate at least one individual responsible for compliance, and to make that person’s business contact details available to the public. You do not have to hire a specialist. In smaller firms, an existing employee can hold the DPO role alongside other duties. What matters is that the role is named, resourced, and reachable, because the DPO is who the PDPC and affected individuals contact first. Publish the contact details on your website and inside your privacy notice. Step 2: Map and Inventory Personal Data You cannot protect data you cannot see. Build a data inventory that records what personal data you hold, where it lives, which systems and people can access it, why you collected it, and how long you keep it. This map is the single most useful artifact in your entire program. It feeds your privacy notice, your retention schedule, your breach assessments, and your vendor reviews. Most compliance failures trace back to a blind spot, a spreadsheet of customer records nobody remembered, or a legacy database still holding data long past its purpose. Step 3: Establish Lawful Basis and Obtain Valid Consent Under the Consent Obligation, you generally need an individual’s consent before you collect, use, or disclose their personal data, and that consent must be tied to a specific, notified purpose. The 2020 amendments added flexibility: deemed consent covers scenarios like contractual necessity, and the legitimate interests exception lets you process data where the benefit outweighs any adverse effect, provided you document the assessment. You cannot make consent to unrelated data uses a condition of providing a service. Important: Bundled consent is a common enforcement trigger. A single checkbox that forces a customer to agree to marketing in order to complete a purchase is not valid consent for the marketing. Separate the purposes, and let people say yes to one without being forced into the other. Step 4: Draft and Publish a Compliant Privacy Notice Your privacy notice is the public expression of how you handle personal data. It should state what you collect, the purposes you collect it for, who you share it with, how long you retain it, and how individuals can contact your DPO or exercise their access and correction rights. Write it in plain language. A notice dense enough to deter reading does not satisfy the spirit of the Notification Obligation, and regulators notice the difference. Step 5: Implement the Notification of Purpose Requirement The Notification Obligation and the Purpose Limitation Obligation work as a pair. You must inform individuals of the purpose before or at the point of collection, and you must then confine your use of the data to that purpose. Practically, that means a clear notice at every collection point: sign-up forms, website pop-ups, contact forms, event registrations. Selling a customer list you gathered for order fulfillment is precisely the kind of

ISO 42001 is the first international standard an organization can be certified against for how it builds, provides, and runs artificial intelligence. It was published in December 2023 by ISO and IEC, and it defines an AI Management System (AIMS) that an accredited auditor can actually inspect. That single fact reshaped the compliance conversation for anyone shipping AI products. A SOC 2 report tells a buyer your data handling is sound. It says nothing about whether your models are governed, your training data is documented, or your automated decisions can be explained. Enterprise procurement teams figured this out fast. AI-specific questionnaires now show up in deals that used to close on a SOC 2 report alone, and buyers increasingly want a recognized certification behind the answers. ISO 42001 is becoming that certification, and Vanta is the platform many AI companies reach for to get there without building a governance program from nothing. What Is ISO 42001 and Why It Matters for AI Companies ISO 42001 at a glance: the first AI management system standard ISO/IEC 42001:2023 specifies the requirements for establishing, maintaining, and continually improving an AIMS. It follows the same Harmonized Structure as ISO 27001 and ISO 9001, so the backbone is familiar: context, leadership, planning, support, operation, performance evaluation, and improvement. The difference sits in the annexes. Annex A defines roughly 38 AI-specific controls across nine areas, covering AI policy, internal roles, resources, impact assessments, lifecycle processes, data management, information for interested parties, use of AI systems, and third-party relationships. Annex B gives implementation guidance, and Annex C lists organizational objectives and risk sources. What makes the standard distinct is that it addresses problems that generic management systems never had to. Model outputs are probabilistic. Training data governance is messy. Automated decisions are hard to explain. Risk does not sit still; it shifts every time a model is retrained or a vendor pushes an update. Who in the AI ecosystem needs ISO 42001 The standard applies across the AI value chain. Providers that build and sell AI systems, developers that create models or components, and deployers that integrate AI into their own products or operations all fall within scope. A Series B startup shipping a generative feature, an enterprise embedding AI in hiring workflows, and a public agency using AI for citizen services can each build an AIMS against the same clauses. For AI-native companies, the pull is commercial before it is regulatory. Certification is turning into a procurement filter. When a large customer’s security review asks how you govern model risk, “we have SOC 2” is no longer a complete answer. How ISO 42001 fits alongside SOC 2, ISO 27001, and the EU AI Act These frameworks are not competitors. They stack. ISO 27001 secures your information. SOC 2 proves your controls to customers. The EU AI Act is binding law with penalties. NIST AI RMF is voluntary guidance. ISO 42001 is the connective tissue that puts an auditable management system around AI specifically. Insider Note: The reason ISO 42001 sells itself in enterprise deals is that it fills a gap SOC 2 was never designed to cover. SOC 2 examines security, availability, and confidentiality. It does not ask whether you ran an AI impact assessment, whether a human reviews high-stakes model outputs, or whether you track which third-party models touch customer data. Buyers now write those exact questions into vendor questionnaires, and a 42001 certificate answers most of them before the call even starts. Need help implementing ISO 42001 in Vanta? Axipro can guide you from setup to certification readiness. Schedule Free Assessment The Unique AI Compliance Challenges Vanta Solves Managing AI-specific risks across models, data, and vendors Traditional GRC tooling was built for static controls. AI risk is not static. A model that passed review at launch can drift, a new data source can introduce bias, and a fine-tune can reclassify your legal obligations overnight. Vanta’s value for AI companies is treating these as continuous, monitored controls rather than one-time checkboxes, spanning the models you build, the data that feeds them, and the vendors whose models you embed. Keeping pace with evolving global AI regulations The regulatory floor keeps moving. The EU AI Act phases in over several years, US agencies are issuing guidance, and standards bodies are revising their work. Tracking this by hand across eight jurisdictions is not realistic for a lean team. A compliance platform that maps a single control set to multiple frameworks turns that sprawl into something maintainable. Proving trust to enterprise buyers procuring AI products The end goal of most of this work is a shorter sales cycle. Enterprise buyers procuring AI want evidence, not assurances. A live, shareable view of your AI compliance posture answers the questionnaire before it becomes a bottleneck, which is exactly what a Trust Center is built to do. How Vanta Supports ISO 42001 Certification for AI Companies Automated evidence collection mapped to ISO 42001 controls The heaviest part of any certification is evidence. Vanta connects to your cloud, identity, and development stack and pulls control evidence automatically, then maps it to the relevant ISO 42001 clauses and Annex A controls. Instead of screenshotting configurations the week before an audit, you accumulate evidence continuously. That shifts the audit from a scramble into a review. Pre-built policy templates for AI governance ISO 42001 expects documented policies for AI use, roles, and risk management. Building these from a blank page is slow and error-prone. Pre-built AI governance policy templates give teams a defensible starting point they can adapt to their actual operations, which matters when an auditor asks not just whether a policy exists but whether it reflects what you really do. Continuous control monitoring for AI systems Certification is a snapshot. An AIMS is supposed to be alive. Continuous monitoring is where the platform earns its keep, flagging when a control drifts out of compliance so you can fix it before it becomes an audit finding or, worse, a real incident. Cross-mapping ISO 42001

Most companies configure Vanta backwards. They connect integrations first, watch tests turn green, and only then ask which framework they are actually being audited against. By the time the auditor asks for the observation window start date, half the account needs to be rebuilt. The order you set things up in Vanta matters almost as much as what you set up, and getting it wrong costs weeks you do not have before a first audit. This checklist walks through the sequence that actually holds up under audit: the decisions to make before you touch the platform, the sequence of configuration inside it, and the final readiness checks before you hand the account to an auditor. Why a Vanta Implementation Checklist Matters Before Your First Audit Vanta is compliance automation software, not a compliance program. It monitors, syncs, and flags. It does not decide your scope, pick your framework, or tell you when your observation window can safely begin. Those calls are yours, and if you make them after connecting integrations rather than before, you end up rescoping mid-implementation, which resets test history and pushes your audit timeline back by weeks. A first-time implementation typically runs six to twelve weeks from account creation to a fully passing test suite, depending on how much of the underlying control environment already existed. Companies that skip the pre-implementation planning stage and jump straight into connecting AWS and Okta tend to discover, three weeks in, that half their integrations are out of scope, their policies do not match their actual operations, and their observation window needs to restart. Ready for your first audit? Get audit-ready with expert Vanta implementation support. Schedule Pre-Implementation: Foundational Decisions to Make First Define Your Target Framework (e.g., SOC 2, ISO 27001, HIPAA) Every downstream Vanta setting, from which integrations you connect to which policies you publish, depends on the framework you are pursuing. SOC 2 Type II evaluates your controls against the AICPA’s five Trust Services Criteria, security, availability, processing integrity, confidentiality, and privacy, with security as the only mandatory category. ISO 27001 asks you to build a full Information Security Management System (ISMS) under a structured set of clauses, backed by a broader set of technical, physical, and organizational controls in Annex A. HIPAA and PCI DSS bring their own control sets tied to specific data types, protected health information and cardholder data, respectively. If your customers are asking for a specific report, let that drive the decision rather than defaulting to whichever framework has the most templates in Vanta’s library. A fintech company with enterprise banking customers may need SOC 2 first and PCI DSS second. A healthcare SaaS vendor almost always needs HIPAA regardless of what else it pursues. Mapping frameworks to actual customer and contractual requirements before configuration saves you from scoping controls you will never use. Important: Choosing multiple frameworks at once is common, but sequencing them wrong creates duplicate work. Configure your primary framework fully, get through a full observation cycle if pursuing Type II, and add secondary frameworks once your evidence collection habits are established. Vanta will map shared controls across frameworks automatically, but only once both are active in the account. Set Your Audit Timeline and Observation Window If you are pursuing SOC 2 Type I, there is no observation window. The audit evaluates whether your controls are designed correctly as of a single point in time, and you can move to audit as soon as your tests pass. SOC 2 Type II is different: the observation window, also called the audit window or monitoring period, is the span during which the auditor samples evidence to confirm your controls actually operated, not just that they existed on paper. For a first Type II audit, a three to six month window is standard. Mature organizations settling into an annual cadence typically move to a full twelve-month window once they have proven consistent operation. Do not start the observation window until you are confident your controls are actually running as designed. Auditors can sample any event from the first day of the window forward, and a control failure in week two of a six-month window is just as damaging to your report as one in week twenty. This is the single most common timeline mistake first-time customers make in Vanta: they start the clock the day they finish connecting integrations, before policies are published, before HR sync is confirmed, and before access reviews have actually happened once. Identify Internal Owners and Stakeholders Every control needs a named owner inside Vanta, not a department. “Engineering” is not a control owner. The engineering manager who reviews production access quarterly is. Before you start configuring, map out who owns identity and access management, who owns vendor risk, who owns HR onboarding and offboarding, and who owns policy publication and employee acknowledgment. If your organization is small enough that one person wears several of these hats, that is fine, but it needs to be explicit in the tool, because Vanta’s task assignments and reminder emails route based on these ownership fields. Choose Your Auditor Before You Configure Vanta Auditor selection affects configuration choices that are expensive to reverse. Different CPA firms and ISO certification bodies have different tolerances for exceptions, different expectations around evidence formatting, and different preferences on how granular your control mapping should be. Get your auditor engaged, or at minimum shortlisted, before you finalize your framework scope and observation window in Vanta. Some firms will do a pre-audit readiness call that surfaces scoping issues Vanta’s automated checks will not catch, like whether a particular subprocessor needs to be in scope. Step 1: Configure Company Settings in Vanta Add Company Details and Business Information Start with the basics: legal entity name, headquarters address, description of the service you provide, and the systems that process customer data. This becomes the backbone of your system description, the narrative document that accompanies your SOC 2 report and explains what your company does and how the in-scope systems support

Two controls decide whether your ISO 27001 business continuity plan survives an audit: Annex A 5.29 and Annex A 5.30. One keeps your security controls working while everything else is failing. The other gets your systems back online before the damage becomes permanent. Plenty of teams write a continuity policy that satisfies neither in the way a certification auditor expects, and they discover the gap during the Stage 2 audit, when it is expensive to fix. This article covers what ISO 27001:2022 actually requires for business continuity, the components an auditor will ask to see, the step-by-step build, and the mistakes that turn a continuity plan into a non-conformity. What Is an ISO 27001 Business Continuity Plan? An ISO 27001 business continuity plan is the documented set of procedures that keeps information security effective and critical ICT services available during a disruption. It is not a generic “keep the lights on” binder. Under ISO 27001, the plan protects the confidentiality, integrity, and availability of information when normal operations break down: a ransomware event, a cloud outage, a data center failure, or a supplier collapse. The plan lives inside your Information Security Management System (ISMS). It draws on your risk assessment, your asset register, and your Business Impact Analysis (BIA), and it feeds your disaster recovery procedures. Scope is the part people get wrong. ISO 27001 cares about the information security aspects of continuity, not every operational hiccup a full business continuity program might cover. Why You Need a Business Continuity Plan for ISO 27001 Compliance Downtime is expensive, and the bill arrives fast. For most organizations, the question is not whether a disruption will happen, but how quickly they recover when it does. There is also a hard compliance reason. You cannot certify to ISO 27001 while ignoring continuity. The standard requires you to maintain information security during disruption and to keep ICT able to support recovery, and an auditor will ask for the evidence. A continuity plan is where availability stops being a promise and becomes a tested capability. Let Axipro help you build a business continuity plan that’s practical, compliant, and audit-ready. Strengthen Your Business Continuity Strategy Schedule A Consultation ISO 27001 Requirements Related to Business Continuity Planning ISO/IEC 27001:2022 carries 93 Annex A controls across four categories: organizational, people, physical, and technological. Continuity sits in the organizational set, and two controls do the heavy lifting, supported by two more on the technical side. Annex A 5.29 – Information Security During Disruption A.5.29 requires you to maintain information security at an appropriate level when a disruption hits. The point is that security controls have a habit of degrading under pressure. People disable multi-factor authentication to “speed things up,” logging stops on a failover system, or access controls loosen while everyone scrambles. A.5.29 says the confidentiality and integrity of your information must be maintained even while availability is under threat. It is classed as both a preventive and a corrective control, meaning it should reduce the chance of an incident and also help resolve one already underway. Annex A 5.30 – ICT Readiness for Business Continuity A.5.30 is the technical engine. It requires that your ICT readiness is planned, implemented, maintained, and tested against business continuity objectives and ICT continuity requirements. In plain terms, your servers, networks, applications, and cloud services need a defined recovery path, each with a Recovery Time Objective (RTO) and Recovery Point Objective (RPO), and you need to prove the path works. This control is entirely new in the 2022 revision. It has no precedent in ISO 27001:2013, which is exactly why teams migrating from the older version so often have a gap here. Important: A.5.30 did not exist in ISO 27001:2013. If your continuity documentation was written against the old Annex A 17 cluster and never updated, you are missing a control the auditor will specifically test. Treat ICT readiness as a fresh requirement, not a relabel. Two technological controls back these up. Annex A 8.13 (Information Backup) requires backups to be taken and tested in line with an agreed policy, and Annex A 8.14 (Redundancy of Information Processing Facilities) covers the failover and redundancy that let critical systems keep running when a component dies. Relationship Between ISO 27001 and ISO 22301 This is where confusion is common. ISO 27001 requires the information security aspects of continuity. ISO 22301 is the dedicated standard for a full Business Continuity Management System (BCMS), covering people, facilities, supply chain, and operations far beyond information security. An ISO 27001 certificate does not certify your wider continuity program. The good news: both standards share the Annex SL high-level structure, so risk assessment, internal audit, management review, and document control carry across. Teams that already run ISO 27001 can layer ISO 22301 on top with far less effort than starting from scratch. Key Components of an ISO 27001 Business Continuity Plan Business Impact Analysis (BIA) The BIA is the foundation. It identifies your critical business processes, the ICT systems they depend on, and the cost of losing each one over time. It is where your recovery objectives come from, not from a vendor datasheet. A BIA also sets the Maximum Tolerable Period of Disruption (MTPD): the point beyond which an activity’s failure causes unacceptable damage. Risk and Disruption Scenario Assessment Your risk assessment identifies what could cause a disruption and how likely it is, feeding the Risk Treatment Plan and the Statement of Applicability (SoA) that records which controls apply. Continuity planning then runs concrete scenarios: ransomware, a regional outage, a key supplier failure, the loss of a data center. Response and Recovery Strategies For each critical system, you define how you will respond and recover: failover to a secondary site, restore from backup, or switch to a manual workaround. This links incident response to crisis management, the executive-level decision-making that kicks in when an incident escalates beyond a routine fix. Roles and Responsibilities Name real people, not departments. “IT will handle it” is the single most common

When researchers found that Microsoft 365 Copilot could be tricked into leaking corporate data from a single email, the flaw got a clean public identifier: CVE-2025-32711, severity 9.3. When a bug hunter coaxed ChatGPT into producing valid Windows product keys by framing the request as a guessing game, it got nothing. Both were prompt injections. Only one is trackable. That Vulnerability Tracking Gap in AI Security, and what it costs defenders, is the subject of this article. What Is a CVE and Why Does It Matter for Software Security? A CVE (Common Vulnerabilities and Exposures) is a unique public identifier for a specific software flaw. It gives the whole industry one name for one bug, so a researcher in Berlin and an analyst in Bahrain know they mean the same thing. The Role of MITRE’s CVE Program in Traditional Vulnerability Management The CVE program is run by the MITRE Corporation, a US nonprofit. Since 1999 it has assigned hundreds of thousands of IDs, each tied to a discrete, reproducible defect in a defined product and version. A CVE is the connective tissue of coordinated disclosure: a researcher reports the flaw, the vendor patches it, the ID is published, and defenders map it to their own assets. Without that shared label, the same bug ends up with three names and no clear owner. The National Vulnerability Database (NVD) and CVSS Scoring The National Vulnerability Database, maintained by NIST, enriches each CVE with a CVSS (Common Vulnerability Scoring System) score from 0 to 10. That lets teams triage: a 9.3 jumps the queue, a 4.0 waits. Why Prompt Injection Breaks the Traditional CVE Model The CVE model assumes a bug lives in code, sits in a version, and can be fixed. Prompt injection violates all three. Prompt Injection as a Class of Attack, Not a Discrete Bug Prompt injection smuggles instructions into the data an LLM reads, so the model follows the attacker rather than the user. OWASP ranks it as LLM01, the top entry in its 2025 Top 10 for LLM Applications. It is a property of how language models work, not one line of faulty code, so you cannot file a CVE against it. A SQL injection either works or it does not. A prompt injection might succeed nine times in ten, fail on the eleventh, then stop working after a silent model update, which makes the “reproducible” part of reporting genuinely hard. Model Versioning vs. Software Versioning Software has clean version numbers. A weight update to a hosted model can ship silently, with no version a researcher can cite. Two calls to “gpt-4o” a week apart may not behave the same way, and there is no changelog to point at. Why “Patching” an LLM Differs From Patching Code Patching code closes a specific hole. A developer rewrites the faulty line, ships the diff, and the exploit path is gone for good. That clean, binary, auditable loop is the entire premise on which the CVE system rests. “Patching” a model offers none of it. There is no single line to fix, because the behavior the attacker abused is the same behavior that makes the model useful: it reads text and follows instructions. A vendor’s only levers, retraining, hardening the system prompt, or wrapping the model in input and output guardrails, all lower the odds of a successful attack rather than removing the possibility. The fix reduces the success rate from 80 percent to 5 percent and marks it as remediated. The hole is narrower, not closed. The recent record shows how thin that margin is. EchoLeak got past Microsoft’s dedicated cross-prompt-injection classifier by hiding its exfiltration channel in reference-style Markdown that the filter did not recognize, and the AgentFlayer exploit slipped through OpenAI’s URL safety check by routing stolen data through trusted Azure Blob Storage links. Each guardrail worked against the obvious version of the attack and fell to a rephrasing. There is a tuning tax on top of that: crank the filters too tight and the model starts refusing legitimate work, so vendors settle for a balance point rather than elimination. The practical takeaway is to treat “we’ve addressed this” as risk reduction, not closure. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule A Free ASSESSMENT The Current State of AI Vulnerability Tracking Several frameworks exist. None is a true registry of individual, citable prompt injection vulnerabilities. OWASP LLM Top 10 and the LLM01 Classification The OWASP GenAI Security Project’s LLM01:2025 entry is the most cited reference point. It is a category, not a catalog: it does not enumerate specific incidents with IDs. MITRE ATLAS for Adversarial AI Threats MITRE ATLAS is an ATT&CK-style knowledge base of adversarial tactics against AI systems, documenting 16 tactics and more than 80 techniques with real-world case studies as of late 2025. It maps how attacks work, but is not a per-vulnerability ledger with scores. AVID (AI Vulnerability Database) and Its Limitations AVID, run by a nonprofit, is the closest thing to a dedicated AI vulnerability database, cataloging failure modes with reproducible evidence. But it leans on community submissions, skews toward bias and broader failure modes, and notes that the definition of an “AI vulnerability” is itself still a working one. Vendor-Specific Disclosures vs. Industry-Wide Registries Disclosure happens vendor by vendor. OpenAI patched the Windows-key jailbreak server-side; Microsoft fixed EchoLeak and issued a CVE. There is no common venue where these land side by side. The Consequences of No Shared Threat Registry for Prompt Injection Fragmented Disclosure Across AI Vendors Each lab discloses on its own terms, on its own blog, if at all. A defender protecting a multi-model stack has to monitor a dozen channels and hope nothing slips by. Duplicate Discovery and Wasted Research Effort Researchers rediscover the same attack repeatedly. The guessing-game jailbreak, the “dead grandma” trick, and other framing attacks are variations on one theme nobody numbered. No Standardized Severity Scoring for

On November 10, 2026, third-party certification becomes mandatory for most small defense contractors that handle Controlled Unclassified Information. That date, the start of Phase 2 of the CMMC rollout, is the one to circle in red. The framework itself has been binding since the 32 CFR program rule took effect on December 16, 2024, and certification clauses began appearing in new contracts on November 10, 2025. Roughly 73 percent of the Defense Industrial Base (DIB) is made up of small businesses, and a 20-person machine shop now faces the same control set as a prime with a dedicated security team. This guide breaks down what the CMMC requirements for small business actually demand: the levels, the controls, the documentation, the real cost, and the route to certification. What Is CMMC and Who Needs to Comply? The Cybersecurity Maturity Model Certification is the Department of Defense’s program for verifying that contractors protect sensitive federal information on their own systems. For years, contractors simply self-attested compliance with NIST Special Publication 800-171. CMMC ends the honor system. It keeps self-assessment for lower-risk work and adds independent audits for everything else. Two regulations run the program. 32 CFR Part 170 defines the structure, the three levels, and the assessment rules. 48 CFR amends the Defense Federal Acquisition Regulation Supplement and embeds CMMC into contracts through clause DFARS 252.204-7021. The first sets the standard, the second makes it a condition of the award. Compliance is not optional based on company size. If you process, store, or transmit Federal Contract Information (FCI) or Controlled Unclassified Information (CUI) in the performance of a DoD contract or subcontract, CMMC applies. The requirement flows down from prime contractors to subcontractors and suppliers at every tier. The main carve-out is for companies that supply only commercially available off-the-shelf (COTS) products. The distinction between the two data types drives everything. FCI is information not meant for public release that is provided by or generated for the government under a contract. CUI is more sensitive: technical drawings, specifications, and procurement data the government requires you to safeguard. Which one you handle sets your level. The fastest way to check is your contract itself. Clauses such as DFARS 252.204-7012, 7019, and 7020 are strong signals that CUI is in scope. CMMC Levels Explained for Small Businesses CMMC has three levels. Most small contractors land at Level 1 or Level 2. Level 3 is reserved for a tiny fraction of the supply chain handling the most sensitive programs. Level 1 covers basic safeguarding of FCI. It maps to the 15 requirements in FAR 52.204-21, things most businesses already do, like using passwords and limiting who can access systems. Self-assessment is permitted and the cost is modest. Level 2 is where the majority of CUI-handling contractors sit. It requires all 110 security requirements in NIST SP 800-171 Revision 2, organized across 14 control families. Some non-prioritized contracts allow an annual self-assessment, but DoD estimates that around 95 percent of Level 2 contractors handle CUI critical enough to require a C3PAO assessment. Level 3 adds 24 selected enhanced requirements from NIST SP 800-172 on top of the full 110, for high-value programs targeted by advanced persistent threats. Assessments are conducted by the government’s Defense Industrial Base Cybersecurity Assessment Center (DIBCAC), and a contractor must already hold Level 2 certification before a Level 3 assessment can begin. Fewer than 1 percent of contractors will need it. To determine your level, read the solicitation and ask your prime directly. If any data you touch is CUI, plan for Level 2 and assume a third-party assessment until a contract tells you otherwise. Prepare Your Business for CMMC Compliance Get ready for the November 2026 CMMC deadline with expert guidance. Talk to a CMMC Expert Core CMMC Requirements Small Businesses Must Meet Level 2 requirements break into 14 control families covering 110 individual requirements and 320 assessment objectives. Access Control and System and Communications Protection are the two heaviest domains. In practice, these families fall into two buckets. The technical controls govern how your systems behave: limiting access to authorized users, requiring multi-factor authentication, logging system activity, hardening configurations, encrypting data, and detecting and responding to incidents. The administrative controls govern how your organization behaves: training staff, screening personnel, controlling physical spaces, assessing risk, and documenting everything. A small business cannot skip a family because it is inconvenient. There is no partial credit and no small-business exemption from the 110. Documentation Requirements for Small Business Compliance Assessors evaluate evidence, not intentions. Two documents anchor the entire effort. The System Security Plan (SSP) describes your environment, your CUI boundary, and how you implement each of the 110 controls. It is a living document and the first thing any assessor reads. The Plan of Action and Milestones (POA&M) records gaps, owners, and timelines for fixing them. CMMC scores Level 2 on a 110-point scale weighted by control importance. A score of at least 88 (80 percent) can earn conditional status, but only if certain high-value controls are fully met. Conditional status gives you 180 days to close every remaining item on your POA&M and pass a closeout assessment. Some critical controls cannot be deferred to a POA&M at all. Beyond the SSP and POA&M, you need written policies and procedures for each domain, plus concrete evidence that controls operate as documented: configuration screenshots, training logs, access reviews, and audit records. Pro Tip: Build your SSP Build your SSP before you spend a dollar on tools. Mapping your current state against all 110 requirements first tells you exactly where the gaps are, so you remediate the right things in the right order instead of buying software you may not need. Technical Requirements and Controls A handful of technical controls account for most assessment failures, and they deserve direct attention. The most effective cost and risk lever is scoping: isolating CUI into a dedicated enclave, a defined set of systems and networks, so the 110 controls apply only there rather than across your
Compliance Hubs
Discover key insights, educational articles, helpful guides and more.
One in five organizations has already suffered a breach traced back to shadow AI. Meanwhile, 63% of breached organizations either have no AI governance policy at all or are still drafting one. Below is a complete, copy-ready shadow AI policy template with twelve sections, plus guidance on adapting it for your company size, your industry, and the regulatory frameworks you answer to. The template assumes one hard truth up front: your employees are already using unapproved AI tools. A policy that pretends adoption hasn’t started yet fails on day one, so this one starts from the assumption that it has. What Is a Shadow AI Policy? A shadow AI policy is a formal document that defines how your organization discovers, evaluates, approves, and governs AI tools that employees adopt outside official IT channels. The term borrows from shadow IT, the older problem of unsanctioned software and hardware, but the AI version carries sharper risks: data pasted into a public model may be retained, used for training, or exposed in ways the organization can’t reverse. The policy does three jobs: it separates approved use from unapproved use, gives employees a fast and visible way to request new tools so the sanctioned route beats the workaround, and spells out what happens when someone crosses the line, including how the organization detects it and responds. Shadow AI Policy vs. General AI Acceptable Use Policy Many organizations already have an AI acceptable use policy (AUP) and assume it covers shadow AI. It usually doesn’t. An AUP tells employees how to behave inside approved tools. A shadow AI policy governs the tools themselves: which ones exist in your environment, which ones are allowed, and what happens with the rest. You need both. The AUP handles conduct; the shadow AI policy handles inventory and control. If you only have room for one document, fold the AUP’s data-handling rules into Section 6 of the template below. Let Axipro help you build a business continuity plan that’s practical, compliant, and audit-ready. Strengthen Your Business Continuity Strategy Schedule A Consultation The Shadow AI Policy Template (Download Link and Copy-Ready Sections) We’ve created a compliance safe template for Shadow AI Policy, use the link below to create a copy and customize for your company: Download The Shadow AI Policy Template → Copy the sections below into your policy management system and replace the bracketed placeholders. The language is plain on purpose. Legalese gets skimmed. Section 1: Purpose and Scope This policy governs the acquisition, approval, and use of artificial intelligence tools, features, and services at [Company]. It applies to all employees, contractors, interns, and third parties with access to [Company] systems or data. It covers standalone AI applications, AI features embedded in existing software, browser extensions, AI agents, APIs, and personal AI accounts used for work purposes, on both corporate and personal devices. The purpose of this policy is to enable productive AI use while protecting [Company] data, customers, and legal obligations. This policy does not prohibit AI. It prohibits ungoverned AI. That last sentence matters. Employees read the purpose statement first, and it decides whether they see the policy as an enabler or a blocker. Section 2: Definitions and Terminology Shadow AI: any AI tool, feature, agent, or service used for work purposes without formal approval under this policy. Approved AI Tool: an AI tool listed in the Approved AI Tools Registry (Section 4) and used under a [Company]-managed account. Personal AI Account: an account on any AI service registered to a personal email address or paid for personally. AI Feature: AI functionality embedded within otherwise approved software (e.g., an AI assistant added to a project management tool), which requires separate evaluation. Sensitive Data: data classified as [Confidential] or [Restricted] under [Company]‘s data classification policy, including the prohibited data classes in Section 6. Define “AI feature” explicitly. Vendors now ship AI additions into already-approved SaaS products every month, and without this definition, those features inherit approval they never earned. Section 3: Roles and Responsibilities The CISO (or designated security lead) owns this policy, maintains the Approved AI Tools Registry, and runs the approval workflow. Department heads ensure their teams know the policy and surface tool requests rather than suppressing them. Legal and Compliance review tools that touch regulated data or fall under the EU AI Act, GDPR, HIPAA, or client contractual restrictions. IT operates detection and monitoring controls (Section 9). Every employee is responsible for using only approved tools for work, reporting unapproved AI use they discover, and requesting new tools through the workflow in Section 7 rather than adopting them directly. Insider Note: In organizations under roughly 200 people, the “CISO” in this section is often the same overworked IT lead who manages laptops. Name a real person, not a title that doesn’t exist yet. A policy that assigns duties to a phantom role is unenforceable, and auditors notice. Section 4: Approved AI Tools Registry [Company] maintains a registry of approved AI tools at [location/URL]. For each tool, the registry records: tool name and vendor, approved use cases, prohibited use cases, permitted data classes, account type (enterprise/team/individual), data retention and training settings, risk tier (Section 5), approval date, and next review date. Only tools listed in the registry may be used for work. Tools not listed are unapproved by default. The registry is reviewed [quarterly]. Keep the registry somewhere employees actually look, such as your intranet homepage or IT help center, not buried in a GRC platform they can’t access. An invisible registry recreates the problem the policy exists to fix. Section 5: Risk Tier Classification (Low, Medium, High) Each tool in the registry is assigned a risk tier. Low: the tool processes only public or internal non-sensitive data, runs under an enterprise agreement with training opt-out, and produces output that a human reviews before use. Approval by IT Security alone. Medium: the tool processes internal business data or connects to [Company] systems via API or integration. Approval by IT Security plus the data owner. High: the
Legacy threat modeling frameworks such as STRIDE were designed for software that behaves the same way over and over again. Agentic AI does no such thing. It can rewrite its own plan mid-task, call external tools, negotiate with other agents, and produce a different output from identical input. MAESTRO exists because none of the legacy threat modeling frameworks were built to handle that. MAESTRO stands for Multi-Agent Environment, Security, Threat, Risk, and Outcome. It is a seven-layer threat modeling framework created specifically for agentic AI systems, and it has become the closest thing the industry has to a standard method for reasoning about agent security. Understanding MAESTRO in the Context of Agentic AI What MAESTRO Stands For Each word in the acronym carries meaning. Multi-Agent Environment signals that the framework models entire ecosystems of interacting agents, not a single model behind an API. Security, Threat, Risk covers the core discipline: identifying attack surfaces, cataloging threats, and assessing likelihood and impact. Outcome is the part most frameworks skip. MAESTRO asks what an attack actually produces in the real world, because an autonomous agent with tool access turns a compromised prompt into a compromised action. The Origin of MAESTRO (Cloud Security Alliance) The Cloud Security Alliance published MAESTRO in February 2025. Its creator is Ken Huang, Co-Chair of the CSA AI Safety Working Groups and CEO of DistributedApps.ai. The CSA has since applied the framework publicly to real systems, including OpenAI’s Responses API and Google’s A2A protocol, which gives practitioners worked examples rather than just theory. The framework is openly published, and the CSA maintains an official companion tool, the MAESTRO Threat Analyzer, on GitHub. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule Free Assessment Why Traditional Frameworks Fall Short for Agentic AI STRIDE, PASTA, LINDDUN, and OCTAVE all share a founding assumption: the system under analysis follows predictable logic with clearly defined boundaries. You draw the data flow diagram, mark the trust boundaries, and enumerate threats against components that behave deterministically. Agentic AI breaks every part of that assumption. Unique Security Challenges of Autonomous Agents Agents introduce three properties that legacy models cannot express. Non-determinism means the same input can produce different behavior, so you cannot enumerate execution paths in advance. Autonomy means the agent makes decisions and takes actions without a human approving each step, which collapses the usual assumption that a person sits between intent and execution. And in multi-agent systems there is often no stable trust boundary: agents delegate to other agents, consume tool outputs from external servers via protocols like the Model Context Protocol (MCP), and update their own memory and goals at runtime. The Gap Between Legacy Frameworks and Agent-Based Systems The practical consequence is coverage gaps. STRIDE has no category for goal manipulation, where an attacker gradually steers what an agent is trying to achieve. PASTA assumes attacker objectives and data flows are fixed, which fails for systems that learn and adapt during operation. LINDDUN addresses privacy but says nothing about agent collusion or memory poisoning. A threat model built purely on these frameworks will pass review and still miss the attacks that matter most in an agentic deployment. How MAESTRO Addresses Agentic-Specific Risks MAESTRO does not discard the older frameworks. It extends them with a layered reference architecture, an AI-specific threat catalog for each layer, and, critically, explicit analysis of how threats propagate between layers. That cross-layer lens is the framework’s real contribution, because most serious agentic incidents are chains: poisoned data influences a model, the model misleads an agent, and the agent takes an unauthorized action three layers away from where the attack started. The Seven Layers of the MAESTRO Framework MAESTRO decomposes any agentic system into seven layers, each with its own threat landscape. Layer 1: Foundation Models The core LLMs or other models the agents reason with. Threats here include adversarial examples, model extraction, backdoored weights, and jailbreaks that bypass safety training. If the model is a third-party API, supply chain risk lives at this layer too. Layer 2: Data Operations Everything the agent ingests, stores, and retrieves: training data, RAG pipelines, vector databases, and agent memory. Data poisoning and memory tampering are the signature threats at this layer, and they are especially dangerous because a poisoned memory persists across sessions and keeps shaping future decisions long after the initial attack. Layer 3: Agent Frameworks The orchestration software that turns a model into an agent: LangChain, CrewAI, AutoGen, custom planners, and tool-calling logic. Threats include prompt injection through tool outputs, insecure tool definitions, and manipulation of the planning loop itself. Layer 4: Deployment Infrastructure The servers, containers, and cloud services the agents run on. The CSA’s threat catalog here reads like traditional cloud security with an agentic twist: compromised container images carrying malicious agent code, Kubernetes orchestration attacks, denial of service against agent runtimes, and tampering with Infrastructure-as-Code templates that provision agent resources. Layer 5: Evaluation and Observability The systems that monitor, evaluate, and debug agent behavior. This layer is often forgotten, and attackers know it. The CSA specifically flags poisoning observability data: manipulating the telemetry fed to monitoring systems so that incidents stay hidden from security teams while malicious activity continues. Layer 6: Security and Compliance MAESTRO treats this as a vertical layer that cuts across all others: identity and access management, guardrails, policy enforcement, and compliance controls. Threats include permission escalation, guardrail bypass, and compromise of the security agents themselves in architectures where AI enforces policy on other AI. Layer 7: Agent Ecosystem The environment where agents interact with users, other agents, and marketplaces. This is where the genuinely novel threats live: agent impersonation, misleading agent capability cards, tool squatting, and collusion between agents to achieve outcomes no single agent was authorized to pursue. Insider Note: In real assessments, Layers 5 and 6 expose the maturity gap fastest. Most teams’ shipping agents can describe their model and their orchestration framework in detail, then
AXIPRO STUDY New Study: Europe is hiring AI builders faster than AI governance professionals Axipro analyzed 3,519 AI-related job postings across eight EU countries. For every professional hired to keep AI lawful, safe and accountable, nearly seven were hired to build more of it, and the gap is widest exactly where you’d least expect. Take EU AI ACT READINESS QUIZZ 16 AI Builders : 1 AI Governors Sweden — Europe’s widest AI governance gap 3,519 Job Postings Analyzed 8 EU Countries 2 Role Categories: Builders vs Governors July 2026 Date of Job Postings Analyzed The findings Finding 1: Sweden hires 16 AI builders for every 1 person to govern them Throughout our data-set we found the same pattern across all eight countries: the more a nation hires to build AI, the less it hires to govern it. France runs eleven builders to every governor. Even Ireland, the most balanced in Europe, looks responsible mainly because the US tech giants headquartered there import global-governance discipline under overlapping DORA and AI Act pressure. 3.5→16 builders hired per governor, Europe’s most balanced country to its least. Ireland 3.5 Germany 5.7 Spain 6.0 Italy 7.1 Netherlands 7.2 Belgium 7.9 France 11.4 Sweden 16:1 0 4 8 12 16 Builders hired per AI governor Source: Axipro, 2026 Sweden has one of the strongest engineering cultures in Europe. It also carries the widest governance gap we measured: sixteen AI builders hired for every person hired to govern them. France sits close behind at eleven to one. The most balanced country, Ireland at 3.5 to one, looks responsible for a reason that has little to do with virtue. The US tech giants headquartered in Dublin import global governance discipline, and they do it under the combined weight of the AI Act and DORA, the EU financial-sector resilience regime in force since January 2025. Engineering strength does nothing to close a governance gap, and it may widen it. A country that ships AI faster produces more systems that fall under the Act’s scope and, on this evidence, fewer people positioned to document, monitor, and defend them. Being good at building AI offers no protection against governing it badly. The countries most confident in their technical talent are running the largest deficit against the law. Explore AI governance hiring by country Click any country to see how many AI builders it hires for every governance professional, and where it ranks against the rest of Europe. Germany — 5.7 builders per governorDE France — 11.4 builders per governorFR Spain — 6.0 builders per governorES Italy — 7.1 builders per governorIT Netherlands — 7.2 builders per governorNL Belgium — 7.9 builders per governorBE Ireland — 3.5 builders per governorIE Sweden — 16 builders per governorSE 3.5 — balanced 16 — widest gap Source: Axipro, 2026 Sweden 16builders for every governance professional Rank 1 of 8 · 20 governance roles vs 319 builder roles posted Only 30% of the AI governance roles name the AI Act Share this Embed this map Copy & paste — links back to Axipro Copy embed code Branded, one paste, backlink included. × Share this country insight Share this AI governance gap X / Twitter LinkedIn Facebook WhatsApp Bluesky Email Copy link Choose a platform or copy the link. A view of the same country-level dataset behind the interactive map: governance roles, builder roles, builder-to-governance ratio, and the share of governance postings that name the EU AI Act. AI governance jobs Europe statistics by country: governance roles, builder roles, builder-to-governance ratio and AI Act mention percentage. Country Governance roles Builder roles Builder-to-governance ratio AI Act mention % Sweden 20 319 16.0:1 30.0% France 39 443 11.4:1 38.5% Belgium 38 299 7.9:1 39.5% Netherlands 61 439 7.2:1 31.1% Italy 40 284 7.1:1 45.0% Spain 64 384 6.0:1 28.1% Germany 88 501 5.7:1 27.3% Ireland 96 335 3.5:1 14.6% Source: Axipro analysis of AI builder, governance and compliance job postings across eight European countries. “AI Act mention %” is the share of governance postings that explicitly name the EU AI Act. Finding 2: The law nobody names. Most AI governance jobs still do not mention the EU AI Act Europe spent years drafting the AI Act. It cleared the European Parliament, survived the Digital Omnibus revisions, and now carries penalties that reach €35 million or 7% of global turnover for the most serious breaches, a ceiling that makes GDPR fines look modest. Yet fewer than three in ten of the governance roles created to handle it actually name the law in the job description. Among builder roles, the figure collapses to one in twenty-five. More than 7 in 10 Governance job descriptions do not mention the EU AI Act. This number rises to 9 in 10 for all AI job descriptions. Despite hiring for governance, risk, privacy, and compliance roles, most employers are not yet translating the EU AI Act into explicit job requirements. That disconnect should stop you. The people being hired to make Europe compliant are, for the most part, not being hired against the Act by name. They are titled around adjacent ideas: risk, ethics, model validation, data protection. Some of that work will map onto the Act’s requirements. Much of it will not, because a role written without the regulation in view rarely produces the conformity assessments, technical documentation, and human-oversight structures the Act specifically demands. Readiness is even thinner than the headcount suggests. Simply counting governance hires overstates how many people are actually working the law. What job descriptions actually name The EU AI Act is visible in governance roles — but still absent from most job ads. Across the laws and frameworks most relevant to AI governance hiring, the EU AI Act appears in fewer than three in ten governance postings, and only 4% of builder postings. Law or framework Governance roles naming it Builder roles naming it All roles naming it Governance mentions EU AI Act 28.5% 4.0% 7.6% 127 GDPR 26.9% 5.7% 9.6% 120 ISO 27001 11.4% 1.3% 2.8% 51
78% of organizations have no formal policies for creating or removing AI agent identities, according to a 2026 report from the Cloud Security Alliance and Oasis Security. The same research found that 92% are not confident that their legacy identity and access management tools can handle the risks agents introduce. Those two numbers describe the problem in full: enterprises are deploying autonomous software that reads email, queries databases, and triggers actions across production systems, and most of them cannot say who authorized it, what it can touch, or how they would prove any of that to an auditor. This is not a future problem. Agents are already operating inside regulated environments governed by the GDPR, HIPAA, SOX, and the EU AI Act. Every access decision an agent makes is a compliance event, whether or not anyone is logging it. This article covers what regulators actually expect, where traditional IAM falls short, and how to build an access framework for AI agents that survives an audit. Understanding the Compliance Landscape for AI Agents Key Regulations Impacting AI Agent Access No regulation says “AI agent” and then hands you a checklist. Instead, agents inherit obligations from every framework that governs the data and systems they touch. Under the GDPR, an agent processing personal data triggers the full set of principles in Article 5: lawfulness, purpose limitation, data minimization, and accountability. If an agent makes decisions that produce legal or similarly significant effects on individuals, Article 22 restrictions on automated decision-making apply as well. HIPAA requires covered entities to implement access controls, audit controls, and integrity protections for electronic protected health information under the Security Rule, and an agent with access to ePHI is subject to the same technical safeguards as a human workforce member. SOX demands that access to financial reporting systems be controlled, segregated, and reviewable, which becomes genuinely difficult when an autonomous agent can touch the general ledger. The EU AI Act adds an AI-specific layer, and its timeline is widely misunderstood. Following the Digital Omnibus agreement, obligations for standalone high-risk systems under Annex III were deferred to December 2, 2027. But the Article 50 transparency obligations still apply from August 2, 2026, meaning agents that interact with people in the EU must disclose their artificial nature on the original schedule. Treating the Omnibus as a blanket delay is one of the most common compliance mistakes being made right now. Important: The Digital Omnibus deferred the high-risk regime, not the whole Act. If an AI agent interacts with users in the EU, the August 2, 2026, transparency requirements were not moved, and the AI Office’s enforcement powers go live on the same date. Do not stand down 2026 workstreams based on headlines about the 2027 deferral. How AI Agents Create New Compliance Risks Agents break the assumptions most compliance programs are built on. A human user requests access, receives a role, and behaves within a predictable envelope. An agent reasons about its own goals, chains tool calls across systems, and can attempt actions its designers never anticipated. It operates at machine speed and machine volume, so a misconfigured permission produces thousands of non-compliant data touches before anyone notices. And because agents frequently run on shared service accounts or borrowed OAuth tokens, attribution collapses: the audit log says the CRM was queried, but not by whom, for what purpose, or under whose authority. The Gap Between Traditional IAM Compliance and Agentic AI Traditional IAM assumes identities are stable, access needs are predictable, and behavior maps to a job description. None of that holds for agents. A 2026 Cloud Security Alliance survey found that 68% of organizations cannot reliably distinguish AI agent activity from human activity in their logs. For a compliance function, that is disqualifying. If you cannot separate agent actions from human actions, you cannot certify access, demonstrate segregation of duties, or respond to a data subject access request with confidence. Core Compliance Requirements for AI Agent Access Auditability and Traceability of Agent Actions Every major framework converges on the same demand: show your work. For agents, a login timestamp is not enough. A defensible audit trail captures the full chain of custody for each action: which agent acted, which human or process delegated the authority, which tool or API was invoked, which data was accessed, and what the outcome was. Gartner’s 2026 Market Guide for what it calls “guardian agents” describes exactly this pattern of recording agent-to-tool-to-target chains for compliance reporting and incident response. Data Protection and Privacy Obligations Agents must operate inside the same data protection perimeter as everything else. That means Data Loss Prevention (DLP) controls apply to agent outputs, not just human uploads. It means an agent’s access to personal data needs a lawful basis, documented before deployment, not reverse-engineered after. And it means retention rules follow the data into whatever context window, vector store, or scratchpad the agent moves it into. Separation of Duties in Autonomous Systems Separation of duties exists so that no single actor can both commit and conceal an error or a fraud. A single agent granted permissions across procurement, approval, and payment reconstitutes exactly the toxic combination SOX controls were designed to prevent, except now it executes at machine speed. The control translates directly: no agent should hold permission sets that a human in the same process would be prohibited from combining, and multi-agent workflows need the same conflict analysis as human role assignments. Consent, Purpose Limitation, and Data Minimization Purpose limitation is the principle that agents most naturally violate. An agent given broad access “to be helpful” will use data collected for one purpose to accomplish another, because nothing in its architecture knows the difference. Compliance-ready agent access means scoping data access to the declared purpose of the task and enforcing that scope technically rather than hoping the system prompt holds. Insider Note: In practice, the purpose limitation failures we see are rarely dramatic. They look like a support agent enriching a ticket with data pulled from the sales
SOC 2 is not a certification, and no auditor will ever hand you a SOC 2 certificate. What you receive at the end of the audit is an attestation report: a detailed document, often 60 to 100 pages long, in which a licensed CPA firm expresses a professional opinion on your controls. That distinction sounds like pedantry until a prospect’s security team asks to see your “certificate” and you have nothing that looks like one. This article explains exactly what a SOC 2 report is, what it contains, how it differs from an ISO 27001 certificate, and how to talk about your SOC 2 status without misrepresenting it. Is SOC 2 a Certification or a Report? The Common Misconception About “SOC 2 Certification” Search volume tells the story: far more people look for “SOC 2 certification” than for “SOC 2 attestation,” and sales teams, procurement questionnaires, and even some auditors use the certification shorthand daily. The misconception is understandable. Every other major framework in the compliance stack, from ISO 27001 to PCI DSS, ends in something that looks like a pass. SOC 2 does not work that way, and treating it as if it does leads to awkward conversations during vendor due diligence. Why SOC 2 Is Technically an Attestation, Not a Certification A certification is a binary judgment issued by an accredited body: you meet the standard, or you do not. SOC 2 sits under the AICPA’s attestation standards, primarily SSAE 18 and its later amendments (SSAE 21 updated the relevant examination sections), specifically AT-C section 105 and AT-C section 205. Under those standards, an independent service auditor examines your controls and reports an opinion on them. Nobody “passes.” The auditor attests to what they found, in writing, with evidence. The output is a report, and the report is the entire deliverable. Understanding the SOC 2 Attestation Model What Is an Attestation Engagement? An attestation engagement is a formal examination in which a practitioner evaluates subject matter prepared by another party against defined criteria, then issues a written conclusion. In SOC 2, the subject matter is your system and its controls, the criteria are the AICPA’s Trust Services Criteria (Security, Availability, Processing Integrity, Confidentiality, and Privacy), and the party preparing the subject matter is you, the service organization. Security is the only mandatory category; the other four are scoped in based on your service commitments. The Role of the AICPA and Licensed CPA Firms The AICPA (American Institute of Certified Public Accountants) owns the SOC framework and the attestation standards behind it, but it does not perform audits and does not issue anything to your company. Only a licensed CPA firm can conduct a SOC 2 examination and sign the resulting opinion. That licensing requirement is the quality mechanism: the firm’s professional liability, independence rules, and peer review obligations stand behind the report. In practice, this means the assurance you get is only as strong as the auditor’s reputation and independence posture, which is why enterprise buyers often look at who signed the report almost as carefully as they look at what it says. How Attestation Differs from Certification and Accreditation The three terms describe different assurance models. Certification means an accredited certification body confirms conformity with a standard and issues a certificate, as happens with ISO 27001. Accreditation is one level up: it is the process by which national bodies, such as those coordinated through the International Accreditation Forum, authorize those certification bodies to certify in the first place. Attestation involves no certificate and no accreditation chain. A CPA firm examines evidence and expresses an opinion under professional standards. The credibility comes from the auditor’s license and independence, not from a badge. What You Actually Receive After a SOC 2 Audit The SOC 2 Attestation Report Explained The deliverable is a confidential, restricted-use document addressed to your management and intended for your customers, their auditors, and other informed parties. It is dense by design. A prospect’s risk team reads it to understand what your system does, which controls you operate, how the auditor tested them, and what the auditor found. It replaces a certificate with something far more useful: evidence. Key Components of the Final Report Independent service auditor’s opinion. The first section, usually two to three pages, states the auditor’s formal conclusion on whether your system description is fairly presented and whether your controls were suitably designed (and, for Type 2, operating effectively). This is the section report readers check first. Management’s assertion. A signed statement in which your leadership formally asserts that the system description is accurate and that controls meet the applicable criteria. SSAE 18 made this management assertion a mandatory element, which means responsibility for the description sits with you, not the auditor. System description. The longest narrative section was prepared by management against the AICPA’s SOC 2 description criteria. It covers the services provided, infrastructure, software, people, data, processes, subservice organizations, and complementary user entity controls. Trust Services Criteria and controls tested. A mapping of each in-scope criterion to the specific controls you operate. This is where scoping decisions become visible: a report covering Security only looks very different from one covering all five categories. Results of testing. For Type 2 reports, a control-by-control table showing the tests the auditor performed and the results, including any exceptions. Sophisticated readers spend most of their time here, because exceptions and the auditor’s response to them reveal more than the opinion page does. What a SOC 2 Report Is NOT (No Certificate, No Logo, No Pass/Fail Badge) There is no official SOC 2 certificate, no numbered credential, and no register of “certified” companies you can be listed in. The AICPA licenses a standard SOC logo that service organizations may display for a limited time after report issuance, but the logo confirms only that an examination took place. It says nothing about the opinion inside. Anyone selling you a “SOC 2 certificate” as a standalone artifact is selling something the framework does not produce. Important: If
The full SIG content library contains 1,936 questions. SIG Lite asks 128 of them. That difference is the entire point: most vendor relationships do not justify a multi-week questionnaire exchange, and SIG Lite exists so risk teams can run standardized due diligence on lower-risk vendors without burning analyst hours or vendor goodwill. What Is SIG Lite? SIG Lite is the streamlined version of the Standardized Information Gathering (SIG) questionnaire, the most widely used third-party risk assessment instrument in the industry. It condenses the full SIG question set into a short, high-level assessment of a vendor’s information security, privacy, and resilience controls. It is a self-assessment, not an audit: the vendor answers, the assessor evaluates, and the completed questionnaire becomes evidence of due diligence in a third-party risk management (TPRM) program. Purpose of the SIG Lite Questionnaire The purpose is speed with consistency. SIG Lite gives an outsourcing organization a broad understanding of a third party’s internal control environment using a standardized question set, so answers are comparable across an entire vendor portfolio. It works either as a complete assessment for low-risk vendors or as a preliminary screen that decides whether a deeper review is warranted. Because every vendor answers the same questions, risk teams can rank, tier, and triage instead of interpreting fifty differently formatted responses. Who Created and Maintains SIG Lite? SIG Lite is owned and maintained by Shared Assessments, a member-driven standards organization formed in 2005 when the Big Four accounting firms and six global banks set out to fix the inefficiency of every company writing its own vendor questionnaire. The SIG is developed through a formal governance process that draws on practitioner feedback and tracks evolving regulations and standards, which is a large part of why it has held its position as the de facto industry template. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule Free Assessment What’s Included in the SIG Lite Questionnaire? Number of Questions and Structure The 2025 release of SIG Lite contains 128 questions. The exact count shifts slightly with each annual update (recent versions have ranged from roughly 126 to 133), so always confirm the version you are working with. Questions are predominantly yes/no with room for comments and references to supporting evidence, and each question maps back to the SIG content library and to external frameworks. SIG Lite ships as a single-worksheet questionnaire, which keeps completion and review manageable. Risk Domains Covered in SIG Lite SIG Lite draws its questions from the same 21 risk domains that structure the entire SIG, grouped into four control areas: Governance and Risk Management, Information Protection, IT Operations and Business Resilience, and Security Incident and Threat Management. In practice, that means high-level coverage of access control, information security policy, data privacy, cloud security, business continuity, incident response, supply chain risk, human resources security, compliance management, and ESG, among others. The breadth is the same as SIG Core; the depth per domain is what gets trimmed. Format and Delivery (Spreadsheet and Toolkit) Historically, the SIG has been delivered as an Excel workbook generated by the SIG Manager, the macro-driven engine inside the SIG Questionnaire Toolkit that lets assessors scope, generate, store, and compare questionnaires. That is changing. In March 2026, Shared Assessments launched SIG EV (Evolution), a browser-based platform that moves questionnaire creation, distribution, comparison, and grading to the cloud while preserving the same content and methodology. Vendors can still respond in Excel, and assessors can upload completed files, so the transition does not break existing workflows. Worth Knowing: SIG Questions & Permissions SIG questions cannot be edited without written permission from Shared Assessments, but assessors can add up to 100 custom questions to a scoped questionnaire. That is usually enough headroom to cover industry-specific requirements without abandoning the standard. When Should You Use SIG Lite? Ideal Vendor Risk Scenarios SIG Lite fits three situations well. First, vendors with no access to sensitive data or critical systems, where a full assessment would be disproportionate. Second, large vendor portfolios, where sending 600-plus questions to every supplier would stall onboarding across the board. Third, early-stage evaluation, where you need enough signal to decide whether a relationship is worth deeper diligence. Low-Risk vs. High-Risk Vendor Assessments The dividing line is data and criticality. A marketing tool that touches no customer records, a facilities contractor, or a niche SaaS product with read-only access to public data can all be assessed adequately with SIG Lite. A payroll processor, a cloud provider hosting production data, or any vendor storing regulated information under HIPAA, PCI DSS, GDPR, or GLBA should get SIG Core. Using Lite on a high-risk vendor is a documented gap waiting to be found in your next audit. Initial vs. In-Depth Risk Screening Many mature programs use SIG Lite as a gate rather than a destination. The Lite response feeds an initial risk score; vendors that trip defined thresholds (a missing incident response plan, no encryption at rest, no independent certification) graduate to SIG Core or a targeted domain-level assessment. This two-stage pattern keeps effort proportional to risk and gives vendors a lighter first touch. SIG Lite vs. SIG Core: Key Differences Both questionnaires come from the same content library and cover the same 21 risk domains. The differences are scope, depth, and effort. Question Count and Scope SIG Lite’s 128 questions sit at the top of the control hierarchy: does a policy exist, is a program in place, and is there independent validation? SIG Core’s 627 questions descend into how each control actually operates. Beyond both sits the full SIG Detail library of 1,936 questions, which assessors use to build custom scopes by regulation, domain, or control family. Depth of Assessment A SIG Lite answer tells you a vendor has an access control program. A SIG Core response tells you how privileged accounts are reviewed, how quickly access is revoked at termination, and how authentication is enforced across environments. If your obligation is
Guides and Reports
AXIPRO STUDY New Study: Europe is hiring AI builders faster than AI governance professionals Axipro analyzed 3,519 AI-related job postings across eight EU countries. For every professional hired to keep AI lawful, safe and accountable, nearly seven were hired to build more of it, and the gap is widest exactly where you’d least expect. Take EU AI ACT READINESS QUIZZ 16 AI Builders : 1 AI Governors Sweden — Europe’s widest AI governance gap 3,519 Job Postings Analyzed 8 EU Countries 2 Role Categories: Builders vs Governors July 2026 Date of Job Postings Analyzed The findings Finding 1: Sweden hires 16 AI builders for every 1 person to govern them Throughout our data-set we found the same pattern across all eight countries: the more a nation hires to build AI, the less it hires to govern it. France runs eleven builders to every governor. Even Ireland, the most balanced in Europe, looks responsible mainly because the US tech giants headquartered there import global-governance discipline under overlapping DORA and AI Act pressure. 3.5→16 builders hired per governor, Europe’s most balanced country to its least. Ireland 3.5 Germany 5.7 Spain 6.0 Italy 7.1 Netherlands 7.2 Belgium 7.9 France 11.4 Sweden 16:1 0 4 8 12 16 Builders hired per AI governor Source: Axipro, 2026 Sweden has one of the strongest engineering cultures in Europe. It also carries the widest governance gap we measured: sixteen AI builders hired for every person hired to govern them. France sits close behind at eleven to one. The most balanced country, Ireland at 3.5 to one, looks responsible for a reason that has little to do with virtue. The US tech giants headquartered in Dublin import global governance discipline, and they do it under the combined weight of the AI Act and DORA, the EU financial-sector resilience regime in force since January 2025. Engineering strength does nothing to close a governance gap, and it may widen it. A country that ships AI faster produces more systems that fall under the Act’s scope and, on this evidence, fewer people positioned to document, monitor, and defend them. Being good at building AI offers no protection against governing it badly. The countries most confident in their technical talent are running the largest deficit against the law. Explore AI governance hiring by country Click any country to see how many AI builders it hires for every governance professional, and where it ranks against the rest of Europe. Germany — 5.7 builders per governorDE France — 11.4 builders per governorFR Spain — 6.0 builders per governorES Italy — 7.1 builders per governorIT Netherlands — 7.2 builders per governorNL Belgium — 7.9 builders per governorBE Ireland — 3.5 builders per governorIE Sweden — 16 builders per governorSE 3.5 — balanced 16 — widest gap Source: Axipro, 2026 Sweden 16builders for every governance professional Rank 1 of 8 · 20 governance roles vs 319 builder roles posted Only 30% of the AI governance roles name the AI Act Share this Embed this map Copy & paste — links back to Axipro Copy embed code Branded, one paste, backlink included. × Share this country insight Share this AI governance gap X / Twitter LinkedIn Facebook WhatsApp Bluesky Email Copy link Choose a platform or copy the link. A view of the same country-level dataset behind the interactive map: governance roles, builder roles, builder-to-governance ratio, and the share of governance postings that name the EU AI Act. AI governance jobs Europe statistics by country: governance roles, builder roles, builder-to-governance ratio and AI Act mention percentage. Country Governance roles Builder roles Builder-to-governance ratio AI Act mention % Sweden 20 319 16.0:1 30.0% France 39 443 11.4:1 38.5% Belgium 38 299 7.9:1 39.5% Netherlands 61 439 7.2:1 31.1% Italy 40 284 7.1:1 45.0% Spain 64 384 6.0:1 28.1% Germany 88 501 5.7:1 27.3% Ireland 96 335 3.5:1 14.6% Source: Axipro analysis of AI builder, governance and compliance job postings across eight European countries. “AI Act mention %” is the share of governance postings that explicitly name the EU AI Act. Finding 2: The law nobody names. Most AI governance jobs still do not mention the EU AI Act Europe spent years drafting the AI Act. It cleared the European Parliament, survived the Digital Omnibus revisions, and now carries penalties that reach €35 million or 7% of global turnover for the most serious breaches, a ceiling that makes GDPR fines look modest. Yet fewer than three in ten of the governance roles created to handle it actually name the law in the job description. Among builder roles, the figure collapses to one in twenty-five. More than 7 in 10 Governance job descriptions do not mention the EU AI Act. This number rises to 9 in 10 for all AI job descriptions. Despite hiring for governance, risk, privacy, and compliance roles, most employers are not yet translating the EU AI Act into explicit job requirements. That disconnect should stop you. The people being hired to make Europe compliant are, for the most part, not being hired against the Act by name. They are titled around adjacent ideas: risk, ethics, model validation, data protection. Some of that work will map onto the Act’s requirements. Much of it will not, because a role written without the regulation in view rarely produces the conformity assessments, technical documentation, and human-oversight structures the Act specifically demands. Readiness is even thinner than the headcount suggests. Simply counting governance hires overstates how many people are actually working the law. What job descriptions actually name The EU AI Act is visible in governance roles — but still absent from most job ads. Across the laws and frameworks most relevant to AI governance hiring, the EU AI Act appears in fewer than three in ten governance postings, and only 4% of builder postings. Law or framework Governance roles naming it Builder roles naming it All roles naming it Governance mentions EU AI Act 28.5% 4.0% 7.6% 127 GDPR 26.9% 5.7% 9.6% 120 ISO 27001 11.4% 1.3% 2.8% 51
SOC 2 Hub
All you need to know about SOC 2 compliance
SOC 2 is not a certification, and no auditor will ever hand you a SOC 2 certificate. What you receive at the end of the audit is an attestation report: a detailed document, often 60 to 100 pages long, in which a licensed CPA firm expresses a professional opinion on your controls. That distinction sounds like pedantry until a prospect’s security team asks to see your “certificate” and you have nothing that looks like one. This article explains exactly what a SOC 2 report is, what it contains, how it differs from an ISO 27001 certificate, and how to talk about your SOC 2 status without misrepresenting it. Is SOC 2 a Certification or a Report? The Common Misconception About “SOC 2 Certification” Search volume tells the story: far more people look for “SOC 2 certification” than for “SOC 2 attestation,” and sales teams, procurement questionnaires, and even some auditors use the certification shorthand daily. The misconception is understandable. Every other major framework in the compliance stack, from ISO 27001 to PCI DSS, ends in something that looks like a pass. SOC 2 does not work that way, and treating it as if it does leads to awkward conversations during vendor due diligence. Why SOC 2 Is Technically an Attestation, Not a Certification A certification is a binary judgment issued by an accredited body: you meet the standard, or you do not. SOC 2 sits under the AICPA’s attestation standards, primarily SSAE 18 and its later amendments (SSAE 21 updated the relevant examination sections), specifically AT-C section 105 and AT-C section 205. Under those standards, an independent service auditor examines your controls and reports an opinion on them. Nobody “passes.” The auditor attests to what they found, in writing, with evidence. The output is a report, and the report is the entire deliverable. Understanding the SOC 2 Attestation Model What Is an Attestation Engagement? An attestation engagement is a formal examination in which a practitioner evaluates subject matter prepared by another party against defined criteria, then issues a written conclusion. In SOC 2, the subject matter is your system and its controls, the criteria are the AICPA’s Trust Services Criteria (Security, Availability, Processing Integrity, Confidentiality, and Privacy), and the party preparing the subject matter is you, the service organization. Security is the only mandatory category; the other four are scoped in based on your service commitments. The Role of the AICPA and Licensed CPA Firms The AICPA (American Institute of Certified Public Accountants) owns the SOC framework and the attestation standards behind it, but it does not perform audits and does not issue anything to your company. Only a licensed CPA firm can conduct a SOC 2 examination and sign the resulting opinion. That licensing requirement is the quality mechanism: the firm’s professional liability, independence rules, and peer review obligations stand behind the report. In practice, this means the assurance you get is only as strong as the auditor’s reputation and independence posture, which is why enterprise buyers often look at who signed the report almost as carefully as they look at what it says. How Attestation Differs from Certification and Accreditation The three terms describe different assurance models. Certification means an accredited certification body confirms conformity with a standard and issues a certificate, as happens with ISO 27001. Accreditation is one level up: it is the process by which national bodies, such as those coordinated through the International Accreditation Forum, authorize those certification bodies to certify in the first place. Attestation involves no certificate and no accreditation chain. A CPA firm examines evidence and expresses an opinion under professional standards. The credibility comes from the auditor’s license and independence, not from a badge. What You Actually Receive After a SOC 2 Audit The SOC 2 Attestation Report Explained The deliverable is a confidential, restricted-use document addressed to your management and intended for your customers, their auditors, and other informed parties. It is dense by design. A prospect’s risk team reads it to understand what your system does, which controls you operate, how the auditor tested them, and what the auditor found. It replaces a certificate with something far more useful: evidence. Key Components of the Final Report Independent service auditor’s opinion. The first section, usually two to three pages, states the auditor’s formal conclusion on whether your system description is fairly presented and whether your controls were suitably designed (and, for Type 2, operating effectively). This is the section report readers check first. Management’s assertion. A signed statement in which your leadership formally asserts that the system description is accurate and that controls meet the applicable criteria. SSAE 18 made this management assertion a mandatory element, which means responsibility for the description sits with you, not the auditor. System description. The longest narrative section was prepared by management against the AICPA’s SOC 2 description criteria. It covers the services provided, infrastructure, software, people, data, processes, subservice organizations, and complementary user entity controls. Trust Services Criteria and controls tested. A mapping of each in-scope criterion to the specific controls you operate. This is where scoping decisions become visible: a report covering Security only looks very different from one covering all five categories. Results of testing. For Type 2 reports, a control-by-control table showing the tests the auditor performed and the results, including any exceptions. Sophisticated readers spend most of their time here, because exceptions and the auditor’s response to them reveal more than the opinion page does. What a SOC 2 Report Is NOT (No Certificate, No Logo, No Pass/Fail Badge) There is no official SOC 2 certificate, no numbered credential, and no register of “certified” companies you can be listed in. The AICPA licenses a standard SOC logo that service organizations may display for a limited time after report issuance, but the logo confirms only that an examination took place. It says nothing about the opinion inside. Anyone selling you a “SOC 2 certificate” as a standalone artifact is selling something the framework does not produce. Important: If

Most teams walk into a SOC 2 audit expecting standard requirements for their password policy: minimum length, 90-day rotation, one uppercase letter, one symbol, and so on. But there is no such checklist. The AICPA never published a list of mandatory password rules, and the federal guidance that most auditors lean on has thrown out half of what passed for best practice a decade ago. Beyond compliance, this is remains a crucial cybersecurity control: Stolen and brute-forced credentials still drive a large share of breaches, and password policies are the main way to mitigate this risk. This guide covers what SOC 2 expects around passwords, where those expectations come from, and how to build a policy that satisfies an auditor without making your security worse. What Are SOC 2 Password Requirements? SOC 2 password requirements are the access controls that a service organization implements to govern how passwords are created, stored, enforced, and retired, all in service of the Trust Services Criteria. The important word is controls, not rules. SOC 2 does not hand you a specification. It asks whether your controls are suitably designed and operating effectively to keep unauthorized people out of your systems. The Role of Passwords in the SOC 2 Trust Services Criteria The Trust Services Criteria, developed by the AICPA, are the evaluation standard for every SOC 2 report. Passwords sit inside the Security category, which is mandatory in all SOC 2 engagements, and specifically inside the Common Criteria series CC6, covering logical and physical access. Passwords are one of the most basic logical access controls you have, and one of the most scrutinized, because CC6 is usually the most evidence-intensive part of the entire audit. Relevant Common Criteria: CC6.1, CC6.2, and CC6.3 CC6.1 covers the controls that restrict logical access to systems, infrastructure, and data, this is where your password policy, MFA enforcement, and account lockout settings live. CC6.2 governs how access is granted, modified, and removed, meaning your provisioning workflows, access reviews, and offboarding processes are all evaluated here. CC6.3 focuses on the removal of access when it is no longer needed and the management of privileged credentials specifically. Together, these three criteria map to the full lifecycle of a credential: creation, ongoing use, and retirement. An auditor working through CC6 will expect evidence at every stage. Does SOC 2 Mandate Specific Password Rules? No. The AICPA is explicit that the Trust Services Criteria do not define the controls an organization must have. You identify and implement controls that meet the criteria, and the auditor evaluates them. That means there is no AICPA-mandated minimum length, no required rotation interval, and no prescribed complexity formula. What the auditor checks is whether your stated controls exist, work, and reasonably prevent unauthorized access. Insider note: Auditors rarely fail you for choosing a 10-character minimum over 12. They fail you when your written policy says one thing and your actual system configuration says another. Consistency between the policy document and the enforced setting matters far more than the specific number. Why Password Requirements Matter for SOC 2 Compliance Preventing Unauthorized Access Credentials are the front door. The 2025 Verizon DBIR found that stolen credentials remained the single most common initial access vector, appearing in 22% of breaches, and that brute force attacks against basic web applications nearly tripled year over year. Strong authentication controls are the difference between an attacker hitting a wall and an attacker walking straight in with a valid login. Reducing Data Breach Risk Weak or reused passwords feed credential stuffing, where attackers replay username and password pairs harvested from earlier breaches against your login pages. Reuse is rampant: research from Microsoft’s Digital Defense Report routinely finds that the majority of people reuse passwords across services. A single leaked password elsewhere becomes a working key to your environment unless your controls catch it. Demonstrating Logical Access Controls to Auditors SOC 2 is an attestation. It is not enough to be secure; you have to prove it with evidence. Well-designed password controls produce exactly the artifacts an auditor wants: configuration screenshots, enforcement logs, MFA reports, and access review records. Good controls and good evidence are two sides of the same coin, and an internal audit process that routinely collects this evidence makes the formal engagement significantly less stressful. Core SOC 2 Password Requirements Although SOC 2 prescribes nothing specific, a defensible password policy almost always addresses the same set of controls. These are what auditors expect to see and what your peers in compliance treat as table stakes. Minimum Password Length Length is the strongest single lever for password entropy, and modern guidance favors it over everything else. A common defensible baseline is at least 12 characters for standard user accounts, with longer requirements for service and admin accounts. NIST SP 800-63B recommends that verifiers support passwords up to 64 characters so that passphrases and password-manager output are never truncated, an important implementation detail that many teams overlook. Password Complexity and Blocklists Old-style complexity rules, one uppercase, one symbol, one number, are fading, and for good reason. They push users toward predictable substitutions without meaningfully raising entropy. The more effective control is a blocklist: screening new passwords against dictionaries of common and previously breached credentials and rejecting matches. Tools like Have I Been Pwned’s Pwned Passwords API make this straightforward to implement. This stops Password1! from sneaking through even though it technically satisfies a legacy complexity rule. Password Rotation and History Forced periodic rotation is the control most teams keep out of habit, and it is also the one that modern guidance most clearly discourages. Rotation pushes users toward predictable patterns, Spring2025 becoming Summer2025, without improving security in any measurable way. Password history settings, which prevent the immediate reuse of recent passwords, still have a place, but blind calendar-based expiry should be replaced with event-driven resets: force a change when there is evidence of compromise, not because the calendar says 90 days have passed. Account Lockout After Failed Login Attempts An account

The identity and access management market will pass $25 billion in 2026, and it is crowded with vendors that all make the same promise: the right people get the right access to the right resources at the right time. The hard part of any IAM solutions comparison is not finding capable products. It is that the leading platforms were each built to solve a different problem first, then expanded outward. Okta started with access. SailPoint started with governance. CyberArk started with privilege. Choose by brand reputation alone, and you risk buying a governance tool to solve an access problem, or paying enterprise prices for capabilities a mid-market team will never switch on. This guide compares the major providers by what they are actually good at, then walks through how to match one to your environment. What Is an IAM Solution? An IAM solution is the set of technologies that manages digital identities and controls what each identity can access. NIST frames the goal simply: ensure the right people and things have the right access to the right resources at the right time. In practice, that breaks into a few core functions: authenticating users (proving they are who they claim), authorizing them (deciding what they may do), and administering the account lifecycle as people join, move, and leave. The category splits into recognizable disciplines. Access management (AM) handles authentication and single sign-on. Identity governance and administration (IGA) handles who should have access and proves it to auditors. Privileged access management (PAM) protects the high-value accounts that can change infrastructure or read sensitive data. Most vendors now sell across these lines, but few are equally strong in all of them. That gap is the whole reason a comparison is worth doing. Why Comparing IAM Solutions Matters in 2026 Identity is now the primary attack surface. Stolen credentials and phishing remain among the top routes attackers use to get inside, which is why identity spending keeps climbing even when other security budgets flatten. The IAM market reached roughly $22 billion in 2025 and is on track for about $25 billion in 2026, growing near 15 percent a year, according to Fortune Business Insights. Two shifts make the comparison harder than it was a few years ago. First, the workforce went hybrid and cloud-first, so identity has to span on-prem systems, SaaS, and multi-cloud at once. Second, machine identities exploded. Your choice of platform now locks in how well you can govern not just employees but the service accounts, tokens, and AI agents multiplying across your environment. Gartner has reported that roughly 48 percent of organizations still lack a written IAM strategy — a serious problem, because a comparison is worth little if it is not anchored to documented requirements. Vendor demos are designed to make every product look like the obvious answer. Key Criteria for Comparing IAM Solutions A useful comparison rests on a consistent scorecard rather than the feature checklists vendors supply. The criteria below are the ones that tend to decide satisfaction two years after purchase. Core Identity and Access Capabilities Start with the fundamentals: single sign-on, multi-factor authentication, lifecycle provisioning and deprovisioning, and access certification. The differentiator in 2026 is adaptive, risk-based authentication that weighs device, location, and behavior before granting access, alongside phishing-resistant methods such as passkeys. A tool that only does password-plus-OTP is already behind. Deployment Options: Cloud-Native, Hybrid, and On-Premises Deployment model shapes cost, speed, and control. Cloud-native SaaS platforms deploy fastest and shift maintenance to the vendor. On-prem suits organizations with strict data-residency rules or deep legacy systems. Hybrid is the common reality, and the question to ask is how gracefully a platform bridges old and new — not whether it claims to. Integration Capabilities with Existing Infrastructure An IAM platform is only as good as its connectors. Look for prebuilt integrations with your core systems, directory services, HR platforms, and major SaaS apps, plus open standards support: SAML, OIDC, SCIM, and increasingly standards for continuous authorization. A thin connector catalog means custom engineering, which is where budgets quietly disappear. Scalability for Enterprise vs. Mid-Market Organizations Scale is not only user count. It is the number of applications, directories, and identity types a platform can govern without performance or administrative strain. Enterprise suites assume a dedicated identity team. Mid-market tools assume a stretched IT generalist. Buying the wrong tier means either paying for unused complexity or hitting a ceiling within two years. Pricing Models and Total Cost of Ownership Headline per-user pricing rarely reflects real cost. Implementation, professional services, connector licensing, premium support, and the internal staff time to run the platform often exceed the subscription itself. Compliance and Audit Support For regulated industries, audit support is a core feature, not a bonus. Strong platforms run access certification campaigns, segregation-of-duties checks, and audit-ready reports aligned with frameworks such as SOX, HIPAA, ISO 27001, and PCI DSS. The NIST Digital Identity Guidelines (SP 800-63, revised in 2025) are a useful reference for the assurance levels your authentication should meet. Vendor Support, Stability, and Roadmap You are buying a multi-year relationship. Financial stability, support quality, and a credible roadmap matter as much as today’s feature set, especially as the market consolidates and converges. A vendor that gets acquired or pivots can leave you maintaining a product on a slow decline. Pro Tip: Comparing Quotes When you compare quotes, normalize them to a three-year total cost of ownership that includes implementation and at least one major version upgrade. Vendors that look cheap per seat sometimes carry the heaviest services bill, and the gap usually shows up in year one, not at signing. IAM Solutions Compared: The Leading Providers The vendors below dominate enterprise shortlists. Each entry notes the problem the platform solves best — which is the most reliable way to read past the marketing. Okta Workforce Identity Cloud Okta is the largest independent identity vendor and was named a Leader in the 2025 Gartner Magic Quadrant for Access Management for the ninth straight year. Its strength is breadth of

Researchers who buy second-hand drives off online marketplaces keep finding the same thing: live data. A widely cited study by Blancco Technology Group found that 42% of used drives sold on eBay still held recoverable information, including financial records and personal data the previous owners assumed was long gone. The drives were not hacked; they were thrown away by organizations that treated deleting a file as the same thing as destroying it. Secure data disposal is where many compliance programs fail. ISO 27001, SOC 2, and GDPR all demand it, but they describe it in different languages, enforce it through different mechanisms, and punish failure in very different ways. This article sets out what each framework requires, where the requirements overlap, and how to run a single disposal program that satisfies all three at once. Why Secure Data Disposal Matters Across Compliance Frameworks Disposal is the last link in the data lifecycle, and the easiest one to skip. An organization can run flawless access controls, encryption, and monitoring for years and still cause a reportable breach the moment one unwiped laptop leaves the building. A recoverable drive in a recycling skip is functionally identical to an open database on the internet, and auditors and regulators know it. Most disposal failures are unforced errors: a control that was already written into policy but never carried through to the actual hardware. The gap between having a disposal policy and proving this specific drive was destroyed is exactly where audits and breach investigations live. Defining Secure Data Disposal: Key Terms and Concepts What Is Secure Data Disposal? Secure data disposal is the end-to-end process of removing data and the equipment that holds it from active use, in a way that prevents its recovery. It covers the full lifecycle end: deletion of data while a system is still live, sanitisation of media that will be reused, physical destruction of media that will not, and the safe handling of equipment that is recycled, returned to a lessor, or sold. Disposal is the goal. The methods are how you get there. What Is Secure Data Destruction? Secure data destruction is the subset of disposal that renders media permanently unusable or its contents mathematically irretrievable. Shredding a drive, pulverising it, incinerating it, or destroying the encryption keys that make an encrypted disk readable are all forms of destruction. Destruction is one route to disposal, and it is the right route when the data is highly sensitive, or the media will never be reused. Secure Data Disposal vs. Secure Data Destruction: What Is the Difference? The distinction matters more than it looks. Disposal is the outcome you owe to every framework: data gone, unrecoverable, equipment handled appropriately. Destruction is just one of the methods. You can dispose of data without destroying the hardware by sanitising a drive thoroughly enough to reuse it. Confusing the two leads to two classic mistakes: destroying assets that could have been securely wiped and reused, and assuming a quick deletion counts as disposal when it does not. Important: Emptying the recycle bin, formatting a drive, or hitting delete does not dispose of data under any of these frameworks. Standard deletion only removes the pointer to the data; the bits remain until they are overwritten. Every framework discussed here expects the data to be unrecoverable, which is a far higher bar than not visible. What ISO 27001 Requires for Secure Data Disposal ISO/IEC 27001 handles disposal through a small cluster of Annex A controls that auditors read as a single process rather than in isolation. The two controls that do most of the work are 7.14 and 8.10. For a deeper look at how these controls fit into a broader compliance program, see our ISO 27001 implementation guide. ISO 27001 Annex A 7.14: Secure Disposal or Re-Use of Equipment Annex A 7.14 is a physical control. Before any equipment is disposed of or reused, the organisation must check whether it holds information assets or licensed software and ensure those are permanently erased or the media physically destroyed. It applies to servers, laptops, desktops, mobile devices, printers, network gear, and any storage media: if it ever processed information, it is in scope. The control replaces the older 2013 clause 11.2.7 and adds explicit expectations around removing identifying markings and handling end-of-occupancy scenarios. ISO 27001 Control 8.10: Information Deletion Annex A 8.10 is a technological control, and it focuses on the data rather than the box. It requires information stored in systems, devices, or media to be deleted when it is no longer required, and rendered unrecoverable. The cleanest way to keep these straight: 8.10 governs the data while it is in use or reaches its retention limit; 7.14 governs the hardware at end of life. Most retention-driven deletion sits under 8.10; most decommissioning sits under 7.14. ISO 27001 Control 8.12: Data Leakage Prevention and Its Role in Disposal Control 8.12 is rarely filed under disposal, but improperly discarded media is one of the oldest data leakage channels there is. A drive that leaves your control with recoverable data on it is a leak, regardless of how it left. Treating disposal as part of your leakage prevention posture forces the right question at the right time: what could walk out the door on this device, and has it actually been removed? Physical Destruction and Irretrievable Erasure Under ISO 27001 ISO 27001 offers two broad routes: physically destroy media that holds information, or erase and overwrite it so retrieval by a malicious party is precluded. The standard cross-references ISO/IEC 27040 for detailed sanitisation methods. The unifying requirement is that recovery should be impractical, not merely inconvenient. Deletion alone never satisfies this. Overwriting, Full-Disk Encryption, and Other Approved Methods Overwriting user-accessible storage with multiple passes is acceptable for many sensitivity levels. Full-disk encryption changes the economics of disposal entirely: if a device is encrypted from day one and the keys are properly managed, secure disposal can be as simple as destroying the keys, a technique known as

A business continuity plan that has never been tested is, to a SOC 2 auditor, a document and nothing more. The Availability criteria do not award credit for a polished plan sitting in a shared drive. They ask for evidence that you ran the plan, watched it work or fail, recorded what happened, and fixed what broke. That gap — between having a plan and proving it works — is where most availability findings originate. Business continuity plan testing for SOC 2 is the exercise that turns your plan into auditable evidence. It maps directly to Availability criterion A1.3, one of the few SOC 2 controls that explicitly requires you to test something rather than merely document it. This guide covers what counts as a valid test, the test types auditors accept, a step-by-step process, the exact evidence you need, and the mistakes that turn a routine review into a finding. What Is Business Continuity Plan Testing in the Context of SOC 2? Business continuity plan (BCP) testing is the structured validation of whether your organization can keep critical operations running — and restore them within defined targets — during a disruption. In a SOC 2 context, the testing is not freeform. It must produce dated, traceable evidence that the recovery procedures in your plan actually work, that the people involved know their roles, and that systems and data come back within your stated recovery objectives. Why SOC 2 Requires Business Continuity Plan Testing SOC 2 is an attestation against the AICPA’s Trust Services Criteria, and the Availability category exists specifically for organizations that make uptime or resilience commitments to customers. A plan you never exercise cannot demonstrate operating effectiveness over the audit period — which is the entire point of a Type 2 examination. Testing is the control that converts a static plan into a recurring, observable activity an auditor can sample. SOC 2 Trust Services Criteria and BCP Testing Requirements Availability is one of the five Trust Services Criteria, and it is optional, included only when your service commitments warrant it. When in scope, it is built around three sub-criteria: A1.1 addresses capacity management. A1.2 addresses recovery infrastructure and backup processes. A1.3 addresses the testing of recovery procedures. BCP testing lives squarely in A1.3, with A1.2 supplying the backups and infrastructure that the test validates. Availability Criteria A1.2 and A1.3 Explained Per the AICPA’s Trust Services Criteria, A1.2 requires the entity to design, implement, operate, and monitor environmental protections, recovery infrastructure, and data backup processes that meet its availability objectives. In plain terms: you need real backups, stored away from production, with recovery infrastructure ready to use. A1.3 then requires the entity to test recovery plan procedures supporting system recovery to meet its objectives. The two work as a pair: A1.2 builds the capability, A1.3 proves it functions. Important: The most common A1.3 gap is not a missing test. It is a test that never validated the recovery objectives. Teams run a tabletop, write “no issues found,” and move on — but the plan claims a 4-hour RTO that no one ever measured against an actual restore. If your plan states recovery targets, your test evidence must show whether you met them. A test that does not measure against your RTO and RPO leaves the most important question unanswered. What Auditors Look for During a BCP Test Review Auditors want proof that the test happened, proof that it was meaningful, and proof that it led somewhere. Concretely, that means a test plan with a defined scenario, a dated record of execution with participants, results measured against your recovery objectives, a list of gaps or issues found, and evidence that those issues were remediated. A test that finds nothing and changes nothing is treated with suspicion — because real tests almost always surface something. Types of Business Continuity Plan Tests Accepted for SOC 2 SOC 2 does not mandate a specific test type. It expects the rigor of the test to match the criticality of what you are protecting. The four common approaches sit on a spectrum from low-effort, low-disruption to high-effort, high-assurance. Tabletop Exercises A tabletop exercise is a facilitated discussion where key personnel talk through a disruption scenario and their responses. It is cheap, fast, and excellent for confirming that people understand their roles and that the plan reads coherently. Its limit is obvious: nobody actually recovers anything. For many organizations a tabletop is a legitimate annual test, especially in the first audit cycle, but auditors expect more rigor as a program matures. Walkthrough and Simulation Tests A simulation applies a specific scenario and asks the team to perform recovery actions, not just describe them. It is more involved than a tabletop and far better at exposing the gaps that only appear when people touch the tools. Simulations are where teams discover that a runbook references a system that was decommissioned, or that the on-call engineer lacks the access the plan assumes. Full Interruption Tests A full interruption test shuts down primary systems and shifts operations entirely to the recovery environment. It is the most comprehensive validation available and the only one that proves your failover genuinely works end to end. It also carries real operational risk, so it demands thorough planning and is usually reserved for mature programs and the most critical systems. Parallel Testing Parallel testing activates recovery systems alongside production without taking the primary offline, then compares the two to confirm the recovery environment performs as expected. It delivers much of the assurance of a full interruption test while sparing the business the disruption. For most SaaS and cloud-hosted services, parallel testing of failover and restore is the sweet spot between confidence and risk. How to Test Your Business Continuity Plan for SOC 2 Compliance The sequence below aligns with the contingency planning process in NIST’s Contingency Planning Guide, SP 800-34, which auditors widely treat as authoritative for resilience practices. Each step produces an artifact, and the artifacts together form

A SOC 2 auditor will not ask whether you have an incident reporting policy. They will ask you to pull a specific incident from the last twelve months and walk them through it: when it was detected, who classified it, when it was escalated, who was notified, and how it was closed. The policy is the easy part. The part that fails audits is the gap between what the document says and what the timestamps actually show. Incident reporting sits at the center of the SOC 2 System Operations criteria, and it is one of the most frequently exception-flagged areas in Type 2 reports. The reason is consistent: teams treat reporting as paperwork generated after the fire is out, rather than as a controlled process that produces evidence at every step. This guide breaks down how to build a reporting process that an auditor can test, sample, and sign off on without a finding. What Is the Incident Reporting Process in SOC 2? The incident reporting process is the documented, repeatable sequence your organization follows from the moment a security event is detected to the moment the incident is formally closed and archived. It governs how events are logged, classified, escalated, communicated, and recorded. Reporting is not a single notification email. It is the connective tissue that links detection, response, and post-incident review into an auditable chain. How SOC 2 Defines a Security Incident SOC 2 does not hand you a rigid statutory definition. It works through the AICPA’s Trust Services Criteria, which frame an incident around a failure, or potential failure, of the system to meet the organization’s service commitments and security objectives. In practice, a security incident is any event that compromises, or could compromise, the confidentiality, integrity, or availability of systems or data. The criteria expect you to define this threshold yourself and apply it consistently, which is precisely what auditors test against. What Qualifies as a Reportable Security Incident Under SOC 2? An event becomes reportable when it crosses the threshold your own policy sets. The distinction matters. A blocked phishing email is a security event. A user who clicked the link and entered credentials is a reportable incident. SOC 2 rewards organizations that draw this line explicitly, because a clear definition is what makes consistent triage possible. Vague language like “significant events will be reported” invites the auditor to ask who decides what counts as significant, and on what basis. Examples of Security Incidents Relevant to SOC 2 Common reportable incidents include unauthorized access to production systems, credential compromise, malware or ransomware infection, data exfiltration or accidental disclosure, denial-of-service events affecting availability, lost or stolen devices holding company data, and misconfigurations that expose data to the public. Vendor and subprocessor breaches that touch your data belong on this list, too, since the criteria extend your responsibility into the supply chain. How Incident Severity Levels Are Established and Classified Severity classification drives everything downstream: how fast you respond, who gets pulled in, and which notification clocks start ticking. Most mature programs use a tiered scheme tied to business impact rather than technical noise. The point is not the labels you choose but the fact that the labels map to defined response times and escalation paths, and that the mapping is documented before an incident occurs, not invented during one. Auditors quietly judge your maturity by how few P1s you declare and how consistently you apply the tiers. A program that labels everything critical looks panicked; one that never escalates looks asleep. The strongest signal is a severity matrix with response-time SLAs next to each tier, and ticket history showing the tiers were actually applied as written. SOC 2 Incident Reporting Requirements There is no single “incident reporting requirement” in SOC 2. The obligation is distributed across several Common Criteria, and the auditor assembles a picture from all of them. Understanding which criteria govern reporting tells you exactly what evidence to keep. Which SOC 2 Trust Services Criteria Govern Incident Reporting? Incident reporting lives mainly in the CC7 (System Operations) series. CC7.2 covers monitoring system components to detect anomalies that may signal an incident. CC7.3 requires you to evaluate detected events to determine whether they are incidents and to take action. CC7.4 governs the response itself, including containment, eradication, and communication. CC7.5 addresses recovery and remediation. Communication obligations also reach into CC2.2 and CC2.3, which deal with internal and external information flow, and third-party incidents implicate CC9.2 on vendor risk. These are points of focus, not a checklist, but auditors use them to frame their testing. For a deeper look at how these criteria map to your broader compliance program, see our SOC 2 compliance guide. What Evidence Do Auditors Expect From Your Incident Reporting Process? Auditors want artifacts with time references, not assertions. That means incident tickets showing detection and closure timestamps, severity classifications with the name of who assigned them, escalation records, communication logs, and post-incident review notes. In a Type 2 examination they will trace one real incident end to end. Evidence pulled from a staging environment, or any artifact with no clear date, gets challenged immediately. Who Is Responsible for Reporting Security Incidents? Everyone reports; a defined role decides. SOC 2 expects that all staff know how to raise a suspected incident, and that a named function, often a security lead or incident commander, owns the determination of severity and the decision to escalate. The auditor will look for evidence that this ownership is real: a RACI chart is fine, but ticket history showing the right person actually classified and closed incidents is better. Step-by-Step SOC 2 Incident Reporting Process The following sequence maps cleanly to the lifecycle in NIST’s Computer Security Incident Handling Guide (SP 800-61), which auditors widely recognize as authoritative. NIST withdrew Revision 2 in April 2025 and released Revision 3, which reorganizes the lifecycle around the six functions of the Cybersecurity Framework 2.0. The underlying steps below remain the same; the framing simply shifts toward continuous risk management.

Most SOC 2 auditors will pick a handful of recent hires from your employee list and request one specific artifact: the completed background check, dated before the start date, sourced from a documented vendor. If you cannot produce it, that is an exception in your report. The control sits inside CC1.4, the Common Criteria provision the AICPA derives from COSO Principle 4, and it is one of the most reliably tested items in a first-year SOC 2 examination. Background screening is not the most technically complex part of SOC 2. It is, however, one of the most procedurally fragile. The policy looks simple on paper. Then a contractor starts a week early because someone needed help shipping a release, the vendor screening gets postponed, and a year later an auditor finds the gap in twenty minutes. This guide explains what SOC 2 actually requires when it comes to background checks, what auditors look for in practice, and how to build a screening programme that holds up under sampling. What Is a SOC 2 Background Check? A SOC 2 background check is the pre-employment screening a service organisation performs to verify that the people it hires can be trusted with access to systems and data inside the SOC 2 scope. It is the operational evidence that supports the abstract principle baked into the Trust Services Criteria: the organisation hires competent people of sound integrity, and it can prove it. In practice, that means a documented check performed by a third party that returns verified information about identity, criminal history, employment history, and, depending on the role, education and credit. The check is run against every new hire before they get logical or physical access to systems within scope. The result is stored, mapped to a named employee, and retrievable on demand. It is worth being clear on one thing: SOC 2 does not prescribe what a background check must contain. The AICPA criteria describe outcomes, not procedures. Your policy is what defines what gets checked, on whom, and how often. The auditor then tests whether you followed your own policy. Why SOC 2 Background Checks Are Important Insider risk is one of the few attack vectors that perimeter security cannot fix. An employee or contractor with legitimate credentials and undisclosed motives sits inside the network from day one. Background checks are how mature security programmes reduce the probability of that scenario before it begins. According to the Verizon 2024 Data Breach Investigations Report, insider threats continue to represent a persistent and costly category of security incidents, reinforcing why personnel vetting remains a foundational control. Auditors care for a related reason. The Control Environment criteria (CC1) sit at the top of the SOC 2 framework because everything else rests on the assumption that the people running the controls are competent and trustworthy. Skip the screening step, and the rest of the audit is built on a weaker foundation. That is why background check evidence is one of the first things auditors sample, and why a missing or late check shows up as an exception even when the rest of your control environment is strong. Insider Note: Auditors do not just check that the screening happened. They check the timing. A background check completed two months into employment is often treated the same as no check at all, because access to in-scope systems was granted before the control was operative. Time stamps matter as much as the document. SOC 2 Background Check Requirements Which Trust Service Criteria Require Background Checks? Background checks are explicitly referenced in the Common Criteria that apply to every SOC 2 engagement, regardless of which optional Trust Services Categories you include. The two controls that matter most are CC1.1 and CC1.4. CC1.1 establishes the entity’s commitment to integrity and ethical values. Background checks support this by demonstrating due diligence in selecting people who meet the organisation’s standards of conduct. CC1.4 is more direct: it derives from COSO Principle 4, which states that the entity demonstrates a commitment to attract, develop, and retain competent individuals in alignment with objectives. Within CC1.4, evaluating individual backgrounds is named as a specific point of focus. That is the hook auditors use. Because these are Common Criteria, they apply regardless of whether you are scoping Security only or adding Availability, Confidentiality, Processing Integrity, or Privacy. There is no version of SOC 2 that escapes them. Who Needs to Be Background Checked for SOC 2? The short answer: anyone whose role gives them logical or physical access to systems, data, or facilities within your SOC 2 scope. The longer answer requires you to draw the line in your own policy and stick to it. At a minimum, this includes full-time employees who join the organisation after the policy is in place. Most mature programmes extend the requirement to part-time employees, contractors who receive credentials, and outsourced personnel performing in-scope work. Vendors are usually handled differently — through contractual flow-down requirements rather than direct screening — but the principle is the same: people inside the trust boundary must be vetted. Roles with privileged access (engineers with production credentials, finance staff with payment system rights, support personnel handling customer data) often warrant deeper screening than baseline roles. Documenting this risk-based approach in your policy is good practice and helps you defend the design of your control during the audit. What Types of Checks Must Be Performed? The Trust Services Criteria do not specify which checks to run. That decision sits with the organisation, informed by role, jurisdiction, and regulatory context. A common baseline for SOC 2 purposes covers several distinct areas. Identity verification confirms the candidate is who they claim to be. Criminal history — national, state, or county-level depending on jurisdiction — flags relevant offences. Employment verification confirms the work history disclosed during hiring. Education verification matters for roles where credentials are material. For positions touching finance, payments, or fiduciary responsibility, a credit check may be appropriate. For roles with global reach, a global

A company that already holds a SOC 2 report has, by most industry estimates, already built somewhere between 60 and 80 percent of what ISO 27001 certification requires. Yet only a small fraction of organizations actually capture that overlap. Teams run the second framework as a fresh project, rewrite policies that already exist, and re-collect evidence they already have on file. The result is paying twice for the same security program. SOC 2 to ISO 27001 mapping is the discipline that stops this. It is a control crosswalk: a structured comparison that shows which SOC 2 controls already satisfy which ISO 27001 requirements, where the genuine gaps sit, and what new work the second framework actually demands. Done well, it turns the second audit from a rebuild into a mapping exercise. What Is SOC 2 to ISO 27001 Mapping? SOC 2 to ISO 27001 mapping links each SOC 2 Trust Services Criterion to its corresponding ISO 27001 clause or Annex A control. The output is a single control library: each control is defined once, tagged to both frameworks, and backed by evidence that both auditors will accept. Worth being clear about upfront: a crosswalk does not make you compliant with anything. It shows where coverage already exists and where it does not. The real work still sits in control design, evidence discipline, and keeping the mapping current as systems and vendors change. A spreadsheet built once and never touched again becomes an audit liability, not an asset. For a structured starting point, a thorough SOC 2 to ISO 27001 gap analysis will surface those liabilities before an auditor does. SOC 2 Trust Services Criteria: An Overview SOC 2 is an attestation framework from the American Institute of Certified Public Accountants (AICPA). It is built on five Trust Services Categories: Security, Availability, Processing Integrity, Confidentiality, and Privacy. Security is the only mandatory category, and every SOC 2 report includes it. The Security category is evaluated through the Common Criteria, written as CC1 through CC9, containing 32 individual criteria in total. CC1 through CC5 cover the control environment, communication, risk assessment, monitoring, and control activities, and they align directly with the COSO internal control framework. CC6 through CC9 are more technology-specific, covering logical and physical access, system operations, change management, and risk mitigation. A SOC 2 audit produces one of two report types. A Type 1 report assesses control design at a single point in time. A Type 2 report assesses both design and operating effectiveness across an observation window, usually 3 to 12 months. A licensed CPA firm issues the report. SOC 2 is an attestation, not a certification, and there is no such thing as a SOC 2 certificate. ISO 27001 Annex A Controls: An Overview ISO/IEC 27001 is the international standard for an information security management system, or ISMS. The current version, ISO 27001:2022, has two distinct layers, and the distinction matters for any mapping effort. Clauses 4 through 10 define the management system itself: organizational context, leadership, planning, risk treatment, support, operations, performance evaluation, and improvement. These clauses are mandatory. Annex A is the second layer, a reference catalogue of 93 controls grouped into four themes: Organizational (37 controls), People (8), Physical (14), and Technological (34). The 2022 revision consolidated the previous 114 controls and 14 domains and added 11 new controls covering areas such as threat intelligence and cloud security. Annex A controls are not all mandatory. Organizations select controls based on a risk assessment and record their choices, including any exclusions and the reasoning behind them, in a Statement of Applicability. Certification is granted by an accredited body, lasts three years, and requires annual surveillance audits. Learn more about what the full certification process involves. Key Structural Differences That Affect Mapping The two frameworks share a large security foundation, but they are built differently, and a mapping that ignores the structural gaps will fail. Understanding ISO 27001 vs SOC 2 at a structural level is the prerequisite for any mapping work worth doing. Four differences matter most. ISO 27001 certifies a management system, while SOC 2 attests to a set of controls. ISO Clauses 4 through 10 have no direct SOC 2 equivalent, because SOC 2 never asks you to prove you run a continuous, governed program; it asks only whether specific controls met specific criteria during the review period. Scope differs too. An ISO 27001 ISMS is expected to cover the organization broadly, while SOC 2 scope is set at the level of a system or service. The outputs differ as well: ISO produces a pass or fail certificate, whereas a SOC 2 report can carry noted exceptions or a qualified opinion and still be a valid, useful report. And because SOC 2 Type 2 tests evidence across a defined window, a control that worked only on audit day will not pass. The most common mapping mistake is treating ISO 27001 as SOC 2 plus a few extra controls. It is not. The Annex A controls map cleanly, but the ISMS management clauses, including internal audit, management review, and continual improvement, are a separate body of work with no SOC 2 starting point. Budget for them as net-new. SOC 2 Common Criteria to ISO 27001 Control Mapping The Common Criteria map to ISO 27001 with a high degree of overlap. The table below is a practical starting crosswalk for the CC series. It lists the primary ISO 27001 references rather than every possible match, and your auditor’s judgment will shape the final mapping. SOC 2 Common Criteria Topic Primary ISO 27001:2022 References CC1 Control Environment Clauses 5 (Leadership), 6 (Planning), A.5.1, A.5.2, A.6.1–A.6.4 CC2 Communication and Information Clause 7.4 (Communication), A.5.1, A.6.3, A.8.2 CC3 Risk Assessment Clause 6.1 (Risk Assessment), A.5.7, A.8.8 CC4 Monitoring Activities Clause 9 (Performance Evaluation), A.5.35, A.5.36, A.8.16 CC5 Control Activities Clause 6.1.3 (Risk Treatment), A.5.37, A.8.9 CC6 Logical and Physical Access A.5.15–A.5.18, A.5.31, A.7.1–A.7.4, A.8.2–A.8.5, A.8.18 CC7 System Operations and Incident Response A.5.24–A.5.28, A.8.15, A.8.16 CC8
ISO 27001 Hub
The latest resources and guides for ISO 27001 Certification
Two controls decide whether your ISO 27001 business continuity plan survives an audit: Annex A 5.29 and Annex A 5.30. One keeps your security controls working while everything else is failing. The other gets your systems back online before the damage becomes permanent. Plenty of teams write a continuity policy that satisfies neither in the way a certification auditor expects, and they discover the gap during the Stage 2 audit, when it is expensive to fix. This article covers what ISO 27001:2022 actually requires for business continuity, the components an auditor will ask to see, the step-by-step build, and the mistakes that turn a continuity plan into a non-conformity. What Is an ISO 27001 Business Continuity Plan? An ISO 27001 business continuity plan is the documented set of procedures that keeps information security effective and critical ICT services available during a disruption. It is not a generic “keep the lights on” binder. Under ISO 27001, the plan protects the confidentiality, integrity, and availability of information when normal operations break down: a ransomware event, a cloud outage, a data center failure, or a supplier collapse. The plan lives inside your Information Security Management System (ISMS). It draws on your risk assessment, your asset register, and your Business Impact Analysis (BIA), and it feeds your disaster recovery procedures. Scope is the part people get wrong. ISO 27001 cares about the information security aspects of continuity, not every operational hiccup a full business continuity program might cover. Why You Need a Business Continuity Plan for ISO 27001 Compliance Downtime is expensive, and the bill arrives fast. For most organizations, the question is not whether a disruption will happen, but how quickly they recover when it does. There is also a hard compliance reason. You cannot certify to ISO 27001 while ignoring continuity. The standard requires you to maintain information security during disruption and to keep ICT able to support recovery, and an auditor will ask for the evidence. A continuity plan is where availability stops being a promise and becomes a tested capability. Let Axipro help you build a business continuity plan that’s practical, compliant, and audit-ready. Strengthen Your Business Continuity Strategy Schedule A Consultation ISO 27001 Requirements Related to Business Continuity Planning ISO/IEC 27001:2022 carries 93 Annex A controls across four categories: organizational, people, physical, and technological. Continuity sits in the organizational set, and two controls do the heavy lifting, supported by two more on the technical side. Annex A 5.29 – Information Security During Disruption A.5.29 requires you to maintain information security at an appropriate level when a disruption hits. The point is that security controls have a habit of degrading under pressure. People disable multi-factor authentication to “speed things up,” logging stops on a failover system, or access controls loosen while everyone scrambles. A.5.29 says the confidentiality and integrity of your information must be maintained even while availability is under threat. It is classed as both a preventive and a corrective control, meaning it should reduce the chance of an incident and also help resolve one already underway. Annex A 5.30 – ICT Readiness for Business Continuity A.5.30 is the technical engine. It requires that your ICT readiness is planned, implemented, maintained, and tested against business continuity objectives and ICT continuity requirements. In plain terms, your servers, networks, applications, and cloud services need a defined recovery path, each with a Recovery Time Objective (RTO) and Recovery Point Objective (RPO), and you need to prove the path works. This control is entirely new in the 2022 revision. It has no precedent in ISO 27001:2013, which is exactly why teams migrating from the older version so often have a gap here. Important: A.5.30 did not exist in ISO 27001:2013. If your continuity documentation was written against the old Annex A 17 cluster and never updated, you are missing a control the auditor will specifically test. Treat ICT readiness as a fresh requirement, not a relabel. Two technological controls back these up. Annex A 8.13 (Information Backup) requires backups to be taken and tested in line with an agreed policy, and Annex A 8.14 (Redundancy of Information Processing Facilities) covers the failover and redundancy that let critical systems keep running when a component dies. Relationship Between ISO 27001 and ISO 22301 This is where confusion is common. ISO 27001 requires the information security aspects of continuity. ISO 22301 is the dedicated standard for a full Business Continuity Management System (BCMS), covering people, facilities, supply chain, and operations far beyond information security. An ISO 27001 certificate does not certify your wider continuity program. The good news: both standards share the Annex SL high-level structure, so risk assessment, internal audit, management review, and document control carry across. Teams that already run ISO 27001 can layer ISO 22301 on top with far less effort than starting from scratch. Key Components of an ISO 27001 Business Continuity Plan Business Impact Analysis (BIA) The BIA is the foundation. It identifies your critical business processes, the ICT systems they depend on, and the cost of losing each one over time. It is where your recovery objectives come from, not from a vendor datasheet. A BIA also sets the Maximum Tolerable Period of Disruption (MTPD): the point beyond which an activity’s failure causes unacceptable damage. Risk and Disruption Scenario Assessment Your risk assessment identifies what could cause a disruption and how likely it is, feeding the Risk Treatment Plan and the Statement of Applicability (SoA) that records which controls apply. Continuity planning then runs concrete scenarios: ransomware, a regional outage, a key supplier failure, the loss of a data center. Response and Recovery Strategies For each critical system, you define how you will respond and recover: failover to a secondary site, restore from backup, or switch to a manual workaround. This links incident response to crisis management, the executive-level decision-making that kicks in when an incident escalates beyond a routine fix. Roles and Responsibilities Name real people, not departments. “IT will handle it” is the single most common

Most companies pursuing ISO 27001 certification cost analysis for the first time will spend between $10,000 and $50,000 in year one, and far less than half of that goes to the auditor. A 50-person SaaS company typically pays $10,000 to $22,000 in certification body fees alone, then doubles or triples that figure in implementation work, tooling, and internal hours before the Stage 2 audit even begins. The wide range exists because ISO 27001 certification cost is not a price tag; it is the sum of a dozen separate decisions: your scope, your security maturity, your certification body, and whether you build the ISMS yourself, hire a consultant, or run it through a compliance automation platform. This article breaks down every one of those costs, stage by stage and region by region, including the ones that never appear in vendor quotes. What Determines ISO 27001 Certification Cost? Six variables drive almost all of the variance between a $10,000 certification and a $150,000 one. Company Size and Employee Count Headcount is the single biggest cost driver because certification bodies calculate audit days (mandays) primarily based on the number of people working within the scope of your Information Security Management System (ISMS). The calculation is not arbitrary: accredited bodies follow the audit time tables in ISO/IEC 27006, which means a 20-person company and a 200-person company will receive structurally different quotes no matter how hard they negotiate. More employees also means more interviews, more evidence sampling, and more Annex A controls applied across more people. Scope and Complexity of the ISMS Scope is the variable you actually control. Your Statement of Scope defines which business units, systems, products, and locations fall inside the ISMS. A scope limited to one product line and the engineering team that runs it costs dramatically less to implement and audit than a whole-of-company scope. Complexity compounds this: bespoke infrastructure, regulated data types, and heavy third-party dependency chains all add controls, evidence, and audit time. Number of Physical and Cloud Locations Each physical site within scope can require its own audit visit, with travel costs on top. Multi-site organisations can reduce this through sampling (more on the square root rule later), but every additional location still adds something. Cloud environments count too: multiple cloud providers, regions, and tenancy models expand the technical scope auditors must cover, even when no travel is involved. Existing Security Maturity A company that already runs access reviews, maintains an asset inventory, and documents its incident response process is buying a much shorter journey than one starting from a blank page. The gap analysis exists precisely to price this difference. Organisations already aligned to SOC 2, NIST CSF, or Cyber Essentials Plus typically reuse 50 to 70 percent of their existing controls and evidence, which translates directly into lower implementation cost. Choice of Certification Body Certification bodies are not interchangeable on price. Large international names like BSI, Bureau Veritas, LRQA, and DNV charge premium day rates, often 30 to 50 percent above smaller accredited bodies, and their brand carries weight with enterprise procurement teams. What matters most is accreditation: a certificate issued by a body accredited by UKAS, ANAB, or another IAF (International Accreditation Forum) member carries international recognition. An unaccredited certificate is cheaper and close to worthless in serious sales conversations. Internal vs. External Implementation Approach The final driver is who does the work. Internal teams cost salary hours. Consultants cost fees. Platforms cost subscriptions. Each approach lands at a very different total, which is why this article dedicates a full section to it below. Average ISO 27001 Certification Cost Ranges The ranges below cover total first-year cost: implementation, tooling, and certification audits combined. They assume an accredited certification body and a sensibly defined scope. Cost for Small Businesses and Startups (1–50 Employees) A focused startup with a single product, cloud-native infrastructure, and a tight scope can realistically certify for $10,000 to $35,000 all-in. Lean implementations using templates or an automation platform sit at the bottom of that range. UK micro-businesses can find UKAS-accredited audit fees starting around £6,250, with day rates near £1,250. Cost for Mid-Sized Organizations (50–250 Employees) This is where most certifications happen, and where costs spread widest. Expect 8 to 12 initial audit days, $30,000 to $80,000 in total first-year spend, and a six to nine month timeline. Multiple departments, more mature customer requirements, and the first real multi-team coordination overhead all show up in the budget. Cost for Large Enterprises (250+ Employees) Enterprise certifications routinely exceed $100,000 in year one once you include program management, multiple sites, and large-scale audits. The audit fee alone can pass $50,000 for complex, multi-site scopes. At this scale, the internal time investment, covered under hidden costs below, often outweighs every external invoice. ISO 27001 Cost Breakdown by Stage Here is where the money actually goes, in roughly the order you will spend it. Cost of Purchasing the ISO 27001 Standard The official ISO/IEC 27001:2022 document costs CHF 155 (roughly $170) from the ISO store. Most teams also buy ISO 27002, the implementation guidance for the Annex A controls, for a similar amount. Budget $300 to $400 for both. Do not skip this purchase: implementing against second-hand summaries of the standard is a common source of audit findings. Gap Analysis Costs A consultant-led gap analysis before committing to anything else runs $2,000 to $10,000 depending on scope, while platform-based readiness assessments are often bundled into the subscription. The output, a clear map of where you stand against every clause and control, is what makes the rest of the budget predictable. ISMS Implementation Costs This is the largest and most variable line item: building the risk assessment, the risk treatment plan, the Statement of Applicability (SoA), and operationalizing the controls you have selected. Done internally, it consumes 200 to 600 hours of staff time over four to eight months. Done with consultants, expect $10,000 to $50,000 in fees for a typical SMB. Documentation and Policy Development Costs ISO 27001 requires a defined set of documented
Researchers who buy second-hand drives off online marketplaces keep finding the same thing: live data. A widely cited study by Blancco Technology Group found that 42% of used drives sold on eBay still held recoverable information, including financial records and personal data the previous owners assumed was long gone. The drives were not hacked; they were thrown away by organizations that treated deleting a file as the same thing as destroying it. Secure data disposal is where many compliance programs fail. ISO 27001, SOC 2, and GDPR all demand it, but they describe it in different languages, enforce it through different mechanisms, and punish failure in very different ways. This article sets out what each framework requires, where the requirements overlap, and how to run a single disposal program that satisfies all three at once. Why Secure Data Disposal Matters Across Compliance Frameworks Disposal is the last link in the data lifecycle, and the easiest one to skip. An organization can run flawless access controls, encryption, and monitoring for years and still cause a reportable breach the moment one unwiped laptop leaves the building. A recoverable drive in a recycling skip is functionally identical to an open database on the internet, and auditors and regulators know it. Most disposal failures are unforced errors: a control that was already written into policy but never carried through to the actual hardware. The gap between having a disposal policy and proving this specific drive was destroyed is exactly where audits and breach investigations live. Defining Secure Data Disposal: Key Terms and Concepts What Is Secure Data Disposal? Secure data disposal is the end-to-end process of removing data and the equipment that holds it from active use, in a way that prevents its recovery. It covers the full lifecycle end: deletion of data while a system is still live, sanitisation of media that will be reused, physical destruction of media that will not, and the safe handling of equipment that is recycled, returned to a lessor, or sold. Disposal is the goal. The methods are how you get there. What Is Secure Data Destruction? Secure data destruction is the subset of disposal that renders media permanently unusable or its contents mathematically irretrievable. Shredding a drive, pulverising it, incinerating it, or destroying the encryption keys that make an encrypted disk readable are all forms of destruction. Destruction is one route to disposal, and it is the right route when the data is highly sensitive, or the media will never be reused. Secure Data Disposal vs. Secure Data Destruction: What Is the Difference? The distinction matters more than it looks. Disposal is the outcome you owe to every framework: data gone, unrecoverable, equipment handled appropriately. Destruction is just one of the methods. You can dispose of data without destroying the hardware by sanitising a drive thoroughly enough to reuse it. Confusing the two leads to two classic mistakes: destroying assets that could have been securely wiped and reused, and assuming a quick deletion counts as disposal when it does not. Important: Emptying the recycle bin, formatting a drive, or hitting delete does not dispose of data under any of these frameworks. Standard deletion only removes the pointer to the data; the bits remain until they are overwritten. Every framework discussed here expects the data to be unrecoverable, which is a far higher bar than not visible. What ISO 27001 Requires for Secure Data Disposal ISO/IEC 27001 handles disposal through a small cluster of Annex A controls that auditors read as a single process rather than in isolation. The two controls that do most of the work are 7.14 and 8.10. For a deeper look at how these controls fit into a broader compliance program, see our ISO 27001 implementation guide. ISO 27001 Annex A 7.14: Secure Disposal or Re-Use of Equipment Annex A 7.14 is a physical control. Before any equipment is disposed of or reused, the organisation must check whether it holds information assets or licensed software and ensure those are permanently erased or the media physically destroyed. It applies to servers, laptops, desktops, mobile devices, printers, network gear, and any storage media: if it ever processed information, it is in scope. The control replaces the older 2013 clause 11.2.7 and adds explicit expectations around removing identifying markings and handling end-of-occupancy scenarios. ISO 27001 Control 8.10: Information Deletion Annex A 8.10 is a technological control, and it focuses on the data rather than the box. It requires information stored in systems, devices, or media to be deleted when it is no longer required, and rendered unrecoverable. The cleanest way to keep these straight: 8.10 governs the data while it is in use or reaches its retention limit; 7.14 governs the hardware at end of life. Most retention-driven deletion sits under 8.10; most decommissioning sits under 7.14. ISO 27001 Control 8.12: Data Leakage Prevention and Its Role in Disposal Control 8.12 is rarely filed under disposal, but improperly discarded media is one of the oldest data leakage channels there is. A drive that leaves your control with recoverable data on it is a leak, regardless of how it left. Treating disposal as part of your leakage prevention posture forces the right question at the right time: what could walk out the door on this device, and has it actually been removed? Physical Destruction and Irretrievable Erasure Under ISO 27001 ISO 27001 offers two broad routes: physically destroy media that holds information, or erase and overwrite it so retrieval by a malicious party is precluded. The standard cross-references ISO/IEC 27040 for detailed sanitisation methods. The unifying requirement is that recovery should be impractical, not merely inconvenient. Deletion alone never satisfies this. Overwriting, Full-Disk Encryption, and Other Approved Methods Overwriting user-accessible storage with multiple passes is acceptable for many sensitivity levels. Full-disk encryption changes the economics of disposal entirely: if a device is encrypted from day one and the keys are properly managed, secure disposal can be as simple as destroying the keys, a technique known as
A business continuity plan that has never been tested is, to a SOC 2 auditor, a document and nothing more. The Availability criteria do not award credit for a polished plan sitting in a shared drive. They ask for evidence that you ran the plan, watched it work or fail, recorded what happened, and fixed what broke. That gap — between having a plan and proving it works — is where most availability findings originate. Business continuity plan testing for SOC 2 is the exercise that turns your plan into auditable evidence. It maps directly to Availability criterion A1.3, one of the few SOC 2 controls that explicitly requires you to test something rather than merely document it. This guide covers what counts as a valid test, the test types auditors accept, a step-by-step process, the exact evidence you need, and the mistakes that turn a routine review into a finding. What Is Business Continuity Plan Testing in the Context of SOC 2? Business continuity plan (BCP) testing is the structured validation of whether your organization can keep critical operations running — and restore them within defined targets — during a disruption. In a SOC 2 context, the testing is not freeform. It must produce dated, traceable evidence that the recovery procedures in your plan actually work, that the people involved know their roles, and that systems and data come back within your stated recovery objectives. Why SOC 2 Requires Business Continuity Plan Testing SOC 2 is an attestation against the AICPA’s Trust Services Criteria, and the Availability category exists specifically for organizations that make uptime or resilience commitments to customers. A plan you never exercise cannot demonstrate operating effectiveness over the audit period — which is the entire point of a Type 2 examination. Testing is the control that converts a static plan into a recurring, observable activity an auditor can sample. SOC 2 Trust Services Criteria and BCP Testing Requirements Availability is one of the five Trust Services Criteria, and it is optional, included only when your service commitments warrant it. When in scope, it is built around three sub-criteria: A1.1 addresses capacity management. A1.2 addresses recovery infrastructure and backup processes. A1.3 addresses the testing of recovery procedures. BCP testing lives squarely in A1.3, with A1.2 supplying the backups and infrastructure that the test validates. Availability Criteria A1.2 and A1.3 Explained Per the AICPA’s Trust Services Criteria, A1.2 requires the entity to design, implement, operate, and monitor environmental protections, recovery infrastructure, and data backup processes that meet its availability objectives. In plain terms: you need real backups, stored away from production, with recovery infrastructure ready to use. A1.3 then requires the entity to test recovery plan procedures supporting system recovery to meet its objectives. The two work as a pair: A1.2 builds the capability, A1.3 proves it functions. Important: The most common A1.3 gap is not a missing test. It is a test that never validated the recovery objectives. Teams run a tabletop, write “no issues found,” and move on — but the plan claims a 4-hour RTO that no one ever measured against an actual restore. If your plan states recovery targets, your test evidence must show whether you met them. A test that does not measure against your RTO and RPO leaves the most important question unanswered. What Auditors Look for During a BCP Test Review Auditors want proof that the test happened, proof that it was meaningful, and proof that it led somewhere. Concretely, that means a test plan with a defined scenario, a dated record of execution with participants, results measured against your recovery objectives, a list of gaps or issues found, and evidence that those issues were remediated. A test that finds nothing and changes nothing is treated with suspicion — because real tests almost always surface something. Types of Business Continuity Plan Tests Accepted for SOC 2 SOC 2 does not mandate a specific test type. It expects the rigor of the test to match the criticality of what you are protecting. The four common approaches sit on a spectrum from low-effort, low-disruption to high-effort, high-assurance. Tabletop Exercises A tabletop exercise is a facilitated discussion where key personnel talk through a disruption scenario and their responses. It is cheap, fast, and excellent for confirming that people understand their roles and that the plan reads coherently. Its limit is obvious: nobody actually recovers anything. For many organizations a tabletop is a legitimate annual test, especially in the first audit cycle, but auditors expect more rigor as a program matures. Walkthrough and Simulation Tests A simulation applies a specific scenario and asks the team to perform recovery actions, not just describe them. It is more involved than a tabletop and far better at exposing the gaps that only appear when people touch the tools. Simulations are where teams discover that a runbook references a system that was decommissioned, or that the on-call engineer lacks the access the plan assumes. Full Interruption Tests A full interruption test shuts down primary systems and shifts operations entirely to the recovery environment. It is the most comprehensive validation available and the only one that proves your failover genuinely works end to end. It also carries real operational risk, so it demands thorough planning and is usually reserved for mature programs and the most critical systems. Parallel Testing Parallel testing activates recovery systems alongside production without taking the primary offline, then compares the two to confirm the recovery environment performs as expected. It delivers much of the assurance of a full interruption test while sparing the business the disruption. For most SaaS and cloud-hosted services, parallel testing of failover and restore is the sweet spot between confidence and risk. How to Test Your Business Continuity Plan for SOC 2 Compliance The sequence below aligns with the contingency planning process in NIST’s Contingency Planning Guide, SP 800-34, which auditors widely treat as authoritative for resilience practices. Each step produces an artifact, and the artifacts together form

31% of organizations have caught former employees accessing SaaS applications after their departure (source). Seventy percent of intellectual property theft happens in the ninety days surrounding a resignation announcement. The pattern is so consistent that auditors now treat termination day as one of the highest-risk windows on the security calendar. This article is a working employee offboarding checklist for IT, security, and HR teams who want to close that window cleanly. It walks through ten steps that revoke access without leaving gaps, then covers edge cases (remote workers, hostile exits, lost devices), the manual-versus-automation tradeoff, and post-offboarding monitoring. Use it as a baseline and adapt it to your environment. What Is Employee Offboarding and Why Does Access Revocation Matter? Employee offboarding is the structured process of separating a person from an organization: removing their access, recovering company property, documenting their exit, and updating records. The access revocation piece is the part where most programs fail quietly. Accounts get disabled in the identity provider but stay active in a dozen SaaS tools. Badges get collected but VPN tokens stay valid. The person is gone; the keys to the building are not. Why Employee Offboarding Is a Critical Security Risk Offboarding fails because access has multiplied faster than the processes designed to manage it. The average enterprise now operates somewhere between 275 and 660 SaaS applications depending on size, with employees touching dozens of them each week. Each application is a separate place that needs to be cleaned up, and each one creates an independent point of failure. The departing employee is a particularly acute version of this risk because the motivation to walk away with something often peaks during the same window that access is supposed to be revoked. The Cost of Leaving Access Open After Departure The financial picture is well documented. The 2025 Ponemon Cost of Insider Risks report puts the average annual cost of insider-related incidents at $17.4 million per organization, with containment taking an average of 81 days. Even when a departed employee never actively misuses their access, the existence of a forgotten account is enough to compromise a SOC 2 audit, trigger a breach notification, or create the credentialed beachhead that an outside attacker eventually exploits. The cases keep appearing. Cash App was breached in 2022 when a former employee accessed the records of 8 million customers after leaving. In May 2024, FinWise Bank disclosed that a former employee accessed internal systems after departure because access had never been fully revoked. Intel sued a former engineer in 2024 for downloading roughly 18,000 sensitive files in the days before he left. Ponemon’s 2025 report found that containment costs scale steeply with time. Incidents resolved in under 30 days averaged about $11 million, while those over 90 days averaged $17 million. The biggest variable is not detection capability. It is how fast access actually came down on day one. Compliance and Legal Implications of Incomplete Offboarding Access revocation is not a “best practice.” It is an explicit control requirement in nearly every framework against which an organization is likely to be audited. NIST SP 800-53 control PS-4 requires that on termination, organizations disable system access within an organization-defined time period, terminate or revoke any authenticators, and retrieve organizational property. ISO/IEC 27001 includes equivalent expectations under its Annex A controls for termination of employment. The AICPA Trust Services Criteria for SOC 2 cover this under Common Criteria CC6.2 and CC6.3, and auditors routinely pull a sample of terminated employees and verify timestamps in the identity provider against the HR system. GDPR adds a separate dimension. If a former employee still has access to the personal data of EU residents, that constitutes unauthorised processing under Article 32, and it is the controller’s responsibility, regardless of intent. HIPAA does the same for protected health information. Whatever the framework, the question an auditor or regulator will ask is the same: how quickly was access revoked, and can you prove it? Who Is Responsible for Employee Offboarding? Offboarding fails most often because no one owns the whole process. Four groups need to be in the loop, and each one has a distinct job. HR and People Operations HR is the source of truth for the termination event. Their job is to capture notice of departure, set the official last day, communicate timing to the rest of the business, and serve as the trigger that starts every downstream task. If HR does not record the termination in the HRIS, nothing automated will fire. IT and Security Teams IT executes the access teardown. They disable accounts in the identity provider, revoke SSO and OAuth tokens, remove SaaS application access, suspend email, and recover devices. Security teams typically run the audit trail and post-offboarding monitoring, and they are the ones answering when an account flagged six months later turns out to belong to a person who left in March. Legal and Compliance Legal handles NDA reminders, IP assignment confirmations, non-disclosure obligations, and any contractual surprises. Compliance owns the documentation: the evidence trail that proves the offboarding actually happened and met the relevant control requirements. For regulated industries this becomes audit evidence; for everyone else it becomes legal cover. Direct Managers Managers know things HR does not. They know which shared drives the person owned, which third-party vendors they had standing access to, which client passwords they may have rotated themselves, and which projects need a transition plan. A solid offboarding process forces the manager into the workflow with a checklist of role-specific items, because no central team can guess them. Employee Offboarding Checklist: 10 Steps to Revoke Access Without Leaving Gaps This is the core sequence. The order matters: starting with notification and inventory before disabling accounts means you do not lock the person out of a system you still need them to hand off. Step 1: Initiate Offboarding Immediately Upon Notice of Departure The moment notice is given — resignation, termination decision, or end of contract — the offboarding workflow should start. This means

Plenty of companies treat an ISO 27001 certificate as proof of GDPR compliance. It is not. The two frameworks overlap heavily, but they answer different questions, and the gap between them is exactly where regulators tend to look. ISO 27001 tells you how to build a defensible security program. GDPR tells you what the law expects when that program touches personal data. Run one without understanding the other, and you will either over-engineer security you do not strictly need, or miss privacy obligations that carry real financial exposure. This article maps where ISO 27001 and GDPR meet, where they part ways, and how to run them as a single coordinated effort rather than two competing projects. What Is ISO 27001? ISO/IEC 27001 is the international standard for an Information Security Management System, or ISMS. The current edition is ISO 27001:2022. It is not a checklist of technical fixes. It is a management framework: a structured, repeatable way to identify information security risks, decide how to treat them, document those decisions, and improve over time. Clauses 4 to 10 of the standard define the mandatory ISMS requirements, covering leadership, risk assessment, internal audit, and management review. Annex A then lists 93 controls grouped into four themes: organisational, people, physical, and technological. You do not implement all 93 by default. You select the controls that address your assessed risks and justify your choices in a document called the Statement of Applicability. Certification against ISO 27001 is voluntary and is granted by an accredited third-party body after an audit. What Is GDPR? The General Data Protection Regulation is European Union law. It has been applied since 25 May 2018, and it applies to any organisation that processes the personal data of people in the EU, wherever that organisation is based. GDPR is fundamentally about the rights of individuals, not just the security of data. It grants people rights over their personal data, including access, correction, erasure and portability. It places obligations on the organisations that decide how data is used (controllers) and those that process it on their behalf (processors). It requires a lawful basis for every processing activity, mandates breach notification, and demands transparency about what happens to people’s information. You do not implement GDPR and receive a certificate. You obey it, and a regulator decides whether you have. Key Differences Between ISO 27001 and GDPR Scope and Purpose ISO 27001 protects all information assets an organisation holds: intellectual property, financial records, operational data, source code and, yes, personal data. Its purpose is the confidentiality, integrity and availability of information in general. GDPR is narrower in one sense and broader in another. It covers only personal data of individuals in the EU, but it protects the person behind the data, not merely the data itself. A system can be flawlessly secure and still violate GDPR. Legal Obligation vs. Voluntary Certification This is the difference that catches people out. GDPR is binding law. If you process EU personal data, compliance is not optional, and there is no opting out. ISO 27001 is a voluntary standard. Organisations pursue it for assurance, for competitive advantage, and because customers increasingly demand it. Crucially, there is no such thing as a GDPR certificate. Regulators assess compliance through investigation and enforcement, not through a badge you can display. Penalties for Non-Compliance GDPR fines run on two tiers under Article 83. Less severe infringements — such as failures around records of processing or breach notification — can reach €10 million or 2% of global annual turnover, whichever is higher. The more serious tier, covering breaches of the core processing principles and data subject rights, can reach €20 million or 4% of global annual turnover. Failing an ISO 27001 audit carries no legal fine at all. The consequence is commercial: you do not get the certificate, or you lose it, and that can cost you contracts. How ISO 27001 and GDPR Align Despite their different purposes, the two frameworks were built on compatible logic, which is why running them together works. Both treat information security as central. GDPR Article 32 requires “appropriate technical and organisational measures” to secure personal data. That phrasing is almost a direct description of what an ISO 27001 ISMS produces. The controls an organisation selects for confidentiality and access already serve the regulation’s security expectations. Both are risk-based. ISO 27001 starts every control decision from a risk assessment. GDPR expects the same proportionality: the measures you apply should match the sensitivity of the data and the likelihood and severity of harm. One risk methodology can serve both, provided you assess personal data processing risks alongside broader security risks. Both demand incident response. ISO 27001’s incident management controls require organisations to detect, assess and respond to security events. GDPR Article 33 requires notifying the supervisory authority of a personal data breach within 72 hours of becoming aware of it. The ISO process is the engine that makes the GDPR deadline achievable. How ISO 27001 Can Help You Comply With GDPR Four areas of an ISMS do direct, practical work toward GDPR compliance. Asset management. ISO 27001 requires an inventory of information and associated assets, with owners assigned. You cannot protect personal data, respond to access requests, or maintain records of processing if you do not know where that data lives. The asset inventory is the foundation for both frameworks. Access control. Identity management, privileged access controls and the principle of least privilege limit who can see personal data. That directly supports the GDPR requirement to ensure confidentiality and to prevent unauthorised access. Operational security. Logging, malware protection, backup and secure configuration keep personal data accurate, available and resistant to compromise. These map cleanly onto the integrity and availability expectations in Article 32. Techniques such as data masking for GDPR and ISO 27001 also sit within this space, reducing exposure without sacrificing operational utility. Incident management. A defined process for detecting and handling security events gives you the evidence trail and the response capability you need to
A company that already holds a SOC 2 report has, by most industry estimates, already built somewhere between 60 and 80 percent of what ISO 27001 certification requires. Yet only a small fraction of organizations actually capture that overlap. Teams run the second framework as a fresh project, rewrite policies that already exist, and re-collect evidence they already have on file. The result is paying twice for the same security program. SOC 2 to ISO 27001 mapping is the discipline that stops this. It is a control crosswalk: a structured comparison that shows which SOC 2 controls already satisfy which ISO 27001 requirements, where the genuine gaps sit, and what new work the second framework actually demands. Done well, it turns the second audit from a rebuild into a mapping exercise. What Is SOC 2 to ISO 27001 Mapping? SOC 2 to ISO 27001 mapping links each SOC 2 Trust Services Criterion to its corresponding ISO 27001 clause or Annex A control. The output is a single control library: each control is defined once, tagged to both frameworks, and backed by evidence that both auditors will accept. Worth being clear about upfront: a crosswalk does not make you compliant with anything. It shows where coverage already exists and where it does not. The real work still sits in control design, evidence discipline, and keeping the mapping current as systems and vendors change. A spreadsheet built once and never touched again becomes an audit liability, not an asset. For a structured starting point, a thorough SOC 2 to ISO 27001 gap analysis will surface those liabilities before an auditor does. SOC 2 Trust Services Criteria: An Overview SOC 2 is an attestation framework from the American Institute of Certified Public Accountants (AICPA). It is built on five Trust Services Categories: Security, Availability, Processing Integrity, Confidentiality, and Privacy. Security is the only mandatory category, and every SOC 2 report includes it. The Security category is evaluated through the Common Criteria, written as CC1 through CC9, containing 32 individual criteria in total. CC1 through CC5 cover the control environment, communication, risk assessment, monitoring, and control activities, and they align directly with the COSO internal control framework. CC6 through CC9 are more technology-specific, covering logical and physical access, system operations, change management, and risk mitigation. A SOC 2 audit produces one of two report types. A Type 1 report assesses control design at a single point in time. A Type 2 report assesses both design and operating effectiveness across an observation window, usually 3 to 12 months. A licensed CPA firm issues the report. SOC 2 is an attestation, not a certification, and there is no such thing as a SOC 2 certificate. ISO 27001 Annex A Controls: An Overview ISO/IEC 27001 is the international standard for an information security management system, or ISMS. The current version, ISO 27001:2022, has two distinct layers, and the distinction matters for any mapping effort. Clauses 4 through 10 define the management system itself: organizational context, leadership, planning, risk treatment, support, operations, performance evaluation, and improvement. These clauses are mandatory. Annex A is the second layer, a reference catalogue of 93 controls grouped into four themes: Organizational (37 controls), People (8), Physical (14), and Technological (34). The 2022 revision consolidated the previous 114 controls and 14 domains and added 11 new controls covering areas such as threat intelligence and cloud security. Annex A controls are not all mandatory. Organizations select controls based on a risk assessment and record their choices, including any exclusions and the reasoning behind them, in a Statement of Applicability. Certification is granted by an accredited body, lasts three years, and requires annual surveillance audits. Learn more about what the full certification process involves. Key Structural Differences That Affect Mapping The two frameworks share a large security foundation, but they are built differently, and a mapping that ignores the structural gaps will fail. Understanding ISO 27001 vs SOC 2 at a structural level is the prerequisite for any mapping work worth doing. Four differences matter most. ISO 27001 certifies a management system, while SOC 2 attests to a set of controls. ISO Clauses 4 through 10 have no direct SOC 2 equivalent, because SOC 2 never asks you to prove you run a continuous, governed program; it asks only whether specific controls met specific criteria during the review period. Scope differs too. An ISO 27001 ISMS is expected to cover the organization broadly, while SOC 2 scope is set at the level of a system or service. The outputs differ as well: ISO produces a pass or fail certificate, whereas a SOC 2 report can carry noted exceptions or a qualified opinion and still be a valid, useful report. And because SOC 2 Type 2 tests evidence across a defined window, a control that worked only on audit day will not pass. The most common mapping mistake is treating ISO 27001 as SOC 2 plus a few extra controls. It is not. The Annex A controls map cleanly, but the ISMS management clauses, including internal audit, management review, and continual improvement, are a separate body of work with no SOC 2 starting point. Budget for them as net-new. SOC 2 Common Criteria to ISO 27001 Control Mapping The Common Criteria map to ISO 27001 with a high degree of overlap. The table below is a practical starting crosswalk for the CC series. It lists the primary ISO 27001 references rather than every possible match, and your auditor’s judgment will shape the final mapping. SOC 2 Common Criteria Topic Primary ISO 27001:2022 References CC1 Control Environment Clauses 5 (Leadership), 6 (Planning), A.5.1, A.5.2, A.6.1–A.6.4 CC2 Communication and Information Clause 7.4 (Communication), A.5.1, A.6.3, A.8.2 CC3 Risk Assessment Clause 6.1 (Risk Assessment), A.5.7, A.8.8 CC4 Monitoring Activities Clause 9 (Performance Evaluation), A.5.35, A.5.36, A.8.16 CC5 Control Activities Clause 6.1.3 (Risk Treatment), A.5.37, A.8.9 CC6 Logical and Physical Access A.5.15–A.5.18, A.5.31, A.7.1–A.7.4, A.8.2–A.8.5, A.8.18 CC7 System Operations and Incident Response A.5.24–A.5.28, A.8.15, A.8.16 CC8

Most organisations that fail their first ISO 27001 certification audit don’t fail because their security is lacking. They fail because they lack a systemic approach to their IT systems. ISO 27001:2022 is not a technology exercise. It is a governance framework, and getting certified requires your entire organisation to demonstrate that it manages information security systematically, continuously, and with documented intent. This guide provides a practical, phase-by-phase roadmap to ISO 27001 implementation, covering everything from initial scoping to certification audit preparation. Whether you are building an ISMS from scratch or modernizing a legacy system, the structure below reflects how implementation actually works in practice. The ISO 27001 Implementation Roadmap at a Glance An ISO 27001 implementation roadmap is a structured project plan that takes an organization from its current security posture to certified compliance with ISO/IEC 27001:2022. The roadmap defines phases, deliverables, roles, and timelines, giving your team a clear line of sight from day one through to the certification audit. The standard itself has two components. Clauses 4 through 10 define the mandatory management system requirements: context, leadership, planning, support, operations, performance evaluation, and improvement. Annex A provides a reference catalogue of 93 security controls, organised into four themes: organisational (37 controls), people (8 controls), physical (14 controls), and technological (34 controls). A well-structured roadmap addresses both components in a logical sequence, with risk driving every decision. Pro Tip: What Procurement Teams Actually Accept In our experience at Axipro, most sophisticated procurement teams care about three things: (1) that an independent auditor tested your controls, (2) that the criteria used are recognised and rigorous, and (3) that the report covers a recent period (ideally the last 12 months). Whether the cover page says “SOC 2” or “ISAE 3000” matters less than you think, unless the policy explicitly mandates one or the other. Always ask. Prerequisites and Planning Before You Start Define the Scope of Your ISMS Scope definition is the single most consequential decision in the entire implementation. The scope should reflect the business units, locations, processes, and information assets that are most critical to your organization and most relevant to your customers and stakeholders. A well-defined scope document should identify the boundaries of the ISMS, the interfaces and dependencies with external parties, and any intentional exclusions, with justification for each. Auditors scrutinize scope boundaries carefully. Any exclusion that appears to cherry-pick convenient systems will attract challenge. Form Your ISO 27001 Implementation Team Three roles are non-negotiable: an executive sponsor with authority to allocate resources and enforce decisions; a project manager who owns the day-to-day implementation timeline; and an information security lead who understands both the technical controls and the documentation requirements. Larger organisations may also need departmental representatives from IT, HR, legal, and operations. The most common implementation failure mode is assigning ISO 27001 entirely to the IT team. The standard requires evidence that security is embedded across the organisation. HR owns the people controls. Legal owns the contractual and regulatory requirements. Finance owns the asset valuation. If those functions are not engaged early, you will discover gaps at the worst possible time. If your organisation lacks in-house expertise, working with an experienced ISO 27001 consultant can bridge that gap efficiently. ISO 27001 Implementation Roadmap: Phase-by-Phase Breakdown Phase 1 (2 weeks): Foundation and Planning Phase The first 14 days establish the governance foundation. Key deliverables include a documented ISMS scope; an approved information security policy signed by top management; a defined organisational context covering internal and external issues, interested parties, and legal requirements; and a completed gap assessment that maps your current state against the standard’s requirements. From this list, the gap assessment is the most important document. It identifies which controls are already in place, which need to be built from scratch, and which exist informally but require documentation. Our gap analysis services are designed specifically for this phase, helping organisations cut through the ambiguity and get a clear remediation picture fast. Phase 2 (2 weeks): Implementation Phase The second 14 days focus on risk and documentation. Your team completes the formal risk assessment, identifies and values assets, maps threats and vulnerabilities, and determines risk levels against your defined risk appetite. From this, you produce a Risk Treatment Plan that specifies which risks will be mitigated, accepted, transferred, or avoided, and which Annex A controls address each risk. The Statement of Applicability (SoA) is produced during this phase. It documents all 93 Annex A controls, the justification for including or excluding each one, and the current implementation status. The SoA is typically the first document an auditor requests. It connects your risk assessment to your control selection and demonstrates that your ISMS is risk-driven rather than checklist-driven. Phase 3 (1 to 3 weeks): Audit and Approval The final phase focuses on executing the controls, training staff, and preparing for audit. Technical controls from the risk treatment plan are deployed. Operational procedures are finalised and approved. Security awareness training is delivered to all staff. An ISO 27001 internal audit is conducted to identify nonconformities before the certification body arrives. A management review is completed to demonstrate leadership engagement. This 6-week timeline is achievable for most organizations with existing security foundations and dedicated implementation resources. Rushing the process to meet an arbitrary deadline is the leading cause of audit failures and certification theatre, a situation where documented controls exist only on paper and fall apart under auditor questioning. For a detailed breakdown of where implementations go wrong, see our guide on common pitfalls in ISO 27001. 6-Week Detailed Implementation Timeline Week 1: Project Initiation Secure executive sponsorship in writing. Establish the project team and define roles. Brief key stakeholders on the standard’s requirements and business case. Set up project governance, including a steering committee and regular status reporting. Week 2: Define ISMS Scope and Context and Conduct Gap Assessment Document the organisational context using Clause 4 requirements. Identify interested parties and their requirements. Define and document the ISMS scope boundary. Obtain approval from top management. Assess current security controls
AI Hub
The latest insights into AI implementation and compliance
One in five organizations has already suffered a breach traced back to shadow AI. Meanwhile, 63% of breached organizations either have no AI governance policy at all or are still drafting one. Below is a complete, copy-ready shadow AI policy template with twelve sections, plus guidance on adapting it for your company size, your industry, and the regulatory frameworks you answer to. The template assumes one hard truth up front: your employees are already using unapproved AI tools. A policy that pretends adoption hasn’t started yet fails on day one, so this one starts from the assumption that it has. What Is a Shadow AI Policy? A shadow AI policy is a formal document that defines how your organization discovers, evaluates, approves, and governs AI tools that employees adopt outside official IT channels. The term borrows from shadow IT, the older problem of unsanctioned software and hardware, but the AI version carries sharper risks: data pasted into a public model may be retained, used for training, or exposed in ways the organization can’t reverse. The policy does three jobs: it separates approved use from unapproved use, gives employees a fast and visible way to request new tools so the sanctioned route beats the workaround, and spells out what happens when someone crosses the line, including how the organization detects it and responds. Shadow AI Policy vs. General AI Acceptable Use Policy Many organizations already have an AI acceptable use policy (AUP) and assume it covers shadow AI. It usually doesn’t. An AUP tells employees how to behave inside approved tools. A shadow AI policy governs the tools themselves: which ones exist in your environment, which ones are allowed, and what happens with the rest. You need both. The AUP handles conduct; the shadow AI policy handles inventory and control. If you only have room for one document, fold the AUP’s data-handling rules into Section 6 of the template below. Let Axipro help you build a business continuity plan that’s practical, compliant, and audit-ready. Strengthen Your Business Continuity Strategy Schedule A Consultation The Shadow AI Policy Template (Download Link and Copy-Ready Sections) We’ve created a compliance safe template for Shadow AI Policy, use the link below to create a copy and customize for your company: Download The Shadow AI Policy Template → Copy the sections below into your policy management system and replace the bracketed placeholders. The language is plain on purpose. Legalese gets skimmed. Section 1: Purpose and Scope This policy governs the acquisition, approval, and use of artificial intelligence tools, features, and services at [Company]. It applies to all employees, contractors, interns, and third parties with access to [Company] systems or data. It covers standalone AI applications, AI features embedded in existing software, browser extensions, AI agents, APIs, and personal AI accounts used for work purposes, on both corporate and personal devices. The purpose of this policy is to enable productive AI use while protecting [Company] data, customers, and legal obligations. This policy does not prohibit AI. It prohibits ungoverned AI. That last sentence matters. Employees read the purpose statement first, and it decides whether they see the policy as an enabler or a blocker. Section 2: Definitions and Terminology Shadow AI: any AI tool, feature, agent, or service used for work purposes without formal approval under this policy. Approved AI Tool: an AI tool listed in the Approved AI Tools Registry (Section 4) and used under a [Company]-managed account. Personal AI Account: an account on any AI service registered to a personal email address or paid for personally. AI Feature: AI functionality embedded within otherwise approved software (e.g., an AI assistant added to a project management tool), which requires separate evaluation. Sensitive Data: data classified as [Confidential] or [Restricted] under [Company]‘s data classification policy, including the prohibited data classes in Section 6. Define “AI feature” explicitly. Vendors now ship AI additions into already-approved SaaS products every month, and without this definition, those features inherit approval they never earned. Section 3: Roles and Responsibilities The CISO (or designated security lead) owns this policy, maintains the Approved AI Tools Registry, and runs the approval workflow. Department heads ensure their teams know the policy and surface tool requests rather than suppressing them. Legal and Compliance review tools that touch regulated data or fall under the EU AI Act, GDPR, HIPAA, or client contractual restrictions. IT operates detection and monitoring controls (Section 9). Every employee is responsible for using only approved tools for work, reporting unapproved AI use they discover, and requesting new tools through the workflow in Section 7 rather than adopting them directly. Insider Note: In organizations under roughly 200 people, the “CISO” in this section is often the same overworked IT lead who manages laptops. Name a real person, not a title that doesn’t exist yet. A policy that assigns duties to a phantom role is unenforceable, and auditors notice. Section 4: Approved AI Tools Registry [Company] maintains a registry of approved AI tools at [location/URL]. For each tool, the registry records: tool name and vendor, approved use cases, prohibited use cases, permitted data classes, account type (enterprise/team/individual), data retention and training settings, risk tier (Section 5), approval date, and next review date. Only tools listed in the registry may be used for work. Tools not listed are unapproved by default. The registry is reviewed [quarterly]. Keep the registry somewhere employees actually look, such as your intranet homepage or IT help center, not buried in a GRC platform they can’t access. An invisible registry recreates the problem the policy exists to fix. Section 5: Risk Tier Classification (Low, Medium, High) Each tool in the registry is assigned a risk tier. Low: the tool processes only public or internal non-sensitive data, runs under an enterprise agreement with training opt-out, and produces output that a human reviews before use. Approval by IT Security alone. Medium: the tool processes internal business data or connects to [Company] systems via API or integration. Approval by IT Security plus the data owner. High: the
Legacy threat modeling frameworks such as STRIDE were designed for software that behaves the same way over and over again. Agentic AI does no such thing. It can rewrite its own plan mid-task, call external tools, negotiate with other agents, and produce a different output from identical input. MAESTRO exists because none of the legacy threat modeling frameworks were built to handle that. MAESTRO stands for Multi-Agent Environment, Security, Threat, Risk, and Outcome. It is a seven-layer threat modeling framework created specifically for agentic AI systems, and it has become the closest thing the industry has to a standard method for reasoning about agent security. Understanding MAESTRO in the Context of Agentic AI What MAESTRO Stands For Each word in the acronym carries meaning. Multi-Agent Environment signals that the framework models entire ecosystems of interacting agents, not a single model behind an API. Security, Threat, Risk covers the core discipline: identifying attack surfaces, cataloging threats, and assessing likelihood and impact. Outcome is the part most frameworks skip. MAESTRO asks what an attack actually produces in the real world, because an autonomous agent with tool access turns a compromised prompt into a compromised action. The Origin of MAESTRO (Cloud Security Alliance) The Cloud Security Alliance published MAESTRO in February 2025. Its creator is Ken Huang, Co-Chair of the CSA AI Safety Working Groups and CEO of DistributedApps.ai. The CSA has since applied the framework publicly to real systems, including OpenAI’s Responses API and Google’s A2A protocol, which gives practitioners worked examples rather than just theory. The framework is openly published, and the CSA maintains an official companion tool, the MAESTRO Threat Analyzer, on GitHub. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule Free Assessment Why Traditional Frameworks Fall Short for Agentic AI STRIDE, PASTA, LINDDUN, and OCTAVE all share a founding assumption: the system under analysis follows predictable logic with clearly defined boundaries. You draw the data flow diagram, mark the trust boundaries, and enumerate threats against components that behave deterministically. Agentic AI breaks every part of that assumption. Unique Security Challenges of Autonomous Agents Agents introduce three properties that legacy models cannot express. Non-determinism means the same input can produce different behavior, so you cannot enumerate execution paths in advance. Autonomy means the agent makes decisions and takes actions without a human approving each step, which collapses the usual assumption that a person sits between intent and execution. And in multi-agent systems there is often no stable trust boundary: agents delegate to other agents, consume tool outputs from external servers via protocols like the Model Context Protocol (MCP), and update their own memory and goals at runtime. The Gap Between Legacy Frameworks and Agent-Based Systems The practical consequence is coverage gaps. STRIDE has no category for goal manipulation, where an attacker gradually steers what an agent is trying to achieve. PASTA assumes attacker objectives and data flows are fixed, which fails for systems that learn and adapt during operation. LINDDUN addresses privacy but says nothing about agent collusion or memory poisoning. A threat model built purely on these frameworks will pass review and still miss the attacks that matter most in an agentic deployment. How MAESTRO Addresses Agentic-Specific Risks MAESTRO does not discard the older frameworks. It extends them with a layered reference architecture, an AI-specific threat catalog for each layer, and, critically, explicit analysis of how threats propagate between layers. That cross-layer lens is the framework’s real contribution, because most serious agentic incidents are chains: poisoned data influences a model, the model misleads an agent, and the agent takes an unauthorized action three layers away from where the attack started. The Seven Layers of the MAESTRO Framework MAESTRO decomposes any agentic system into seven layers, each with its own threat landscape. Layer 1: Foundation Models The core LLMs or other models the agents reason with. Threats here include adversarial examples, model extraction, backdoored weights, and jailbreaks that bypass safety training. If the model is a third-party API, supply chain risk lives at this layer too. Layer 2: Data Operations Everything the agent ingests, stores, and retrieves: training data, RAG pipelines, vector databases, and agent memory. Data poisoning and memory tampering are the signature threats at this layer, and they are especially dangerous because a poisoned memory persists across sessions and keeps shaping future decisions long after the initial attack. Layer 3: Agent Frameworks The orchestration software that turns a model into an agent: LangChain, CrewAI, AutoGen, custom planners, and tool-calling logic. Threats include prompt injection through tool outputs, insecure tool definitions, and manipulation of the planning loop itself. Layer 4: Deployment Infrastructure The servers, containers, and cloud services the agents run on. The CSA’s threat catalog here reads like traditional cloud security with an agentic twist: compromised container images carrying malicious agent code, Kubernetes orchestration attacks, denial of service against agent runtimes, and tampering with Infrastructure-as-Code templates that provision agent resources. Layer 5: Evaluation and Observability The systems that monitor, evaluate, and debug agent behavior. This layer is often forgotten, and attackers know it. The CSA specifically flags poisoning observability data: manipulating the telemetry fed to monitoring systems so that incidents stay hidden from security teams while malicious activity continues. Layer 6: Security and Compliance MAESTRO treats this as a vertical layer that cuts across all others: identity and access management, guardrails, policy enforcement, and compliance controls. Threats include permission escalation, guardrail bypass, and compromise of the security agents themselves in architectures where AI enforces policy on other AI. Layer 7: Agent Ecosystem The environment where agents interact with users, other agents, and marketplaces. This is where the genuinely novel threats live: agent impersonation, misleading agent capability cards, tool squatting, and collusion between agents to achieve outcomes no single agent was authorized to pursue. Insider Note: In real assessments, Layers 5 and 6 expose the maturity gap fastest. Most teams’ shipping agents can describe their model and their orchestration framework in detail, then
78% of organizations have no formal policies for creating or removing AI agent identities, according to a 2026 report from the Cloud Security Alliance and Oasis Security. The same research found that 92% are not confident that their legacy identity and access management tools can handle the risks agents introduce. Those two numbers describe the problem in full: enterprises are deploying autonomous software that reads email, queries databases, and triggers actions across production systems, and most of them cannot say who authorized it, what it can touch, or how they would prove any of that to an auditor. This is not a future problem. Agents are already operating inside regulated environments governed by the GDPR, HIPAA, SOX, and the EU AI Act. Every access decision an agent makes is a compliance event, whether or not anyone is logging it. This article covers what regulators actually expect, where traditional IAM falls short, and how to build an access framework for AI agents that survives an audit. Understanding the Compliance Landscape for AI Agents Key Regulations Impacting AI Agent Access No regulation says “AI agent” and then hands you a checklist. Instead, agents inherit obligations from every framework that governs the data and systems they touch. Under the GDPR, an agent processing personal data triggers the full set of principles in Article 5: lawfulness, purpose limitation, data minimization, and accountability. If an agent makes decisions that produce legal or similarly significant effects on individuals, Article 22 restrictions on automated decision-making apply as well. HIPAA requires covered entities to implement access controls, audit controls, and integrity protections for electronic protected health information under the Security Rule, and an agent with access to ePHI is subject to the same technical safeguards as a human workforce member. SOX demands that access to financial reporting systems be controlled, segregated, and reviewable, which becomes genuinely difficult when an autonomous agent can touch the general ledger. The EU AI Act adds an AI-specific layer, and its timeline is widely misunderstood. Following the Digital Omnibus agreement, obligations for standalone high-risk systems under Annex III were deferred to December 2, 2027. But the Article 50 transparency obligations still apply from August 2, 2026, meaning agents that interact with people in the EU must disclose their artificial nature on the original schedule. Treating the Omnibus as a blanket delay is one of the most common compliance mistakes being made right now. Important: The Digital Omnibus deferred the high-risk regime, not the whole Act. If an AI agent interacts with users in the EU, the August 2, 2026, transparency requirements were not moved, and the AI Office’s enforcement powers go live on the same date. Do not stand down 2026 workstreams based on headlines about the 2027 deferral. How AI Agents Create New Compliance Risks Agents break the assumptions most compliance programs are built on. A human user requests access, receives a role, and behaves within a predictable envelope. An agent reasons about its own goals, chains tool calls across systems, and can attempt actions its designers never anticipated. It operates at machine speed and machine volume, so a misconfigured permission produces thousands of non-compliant data touches before anyone notices. And because agents frequently run on shared service accounts or borrowed OAuth tokens, attribution collapses: the audit log says the CRM was queried, but not by whom, for what purpose, or under whose authority. The Gap Between Traditional IAM Compliance and Agentic AI Traditional IAM assumes identities are stable, access needs are predictable, and behavior maps to a job description. None of that holds for agents. A 2026 Cloud Security Alliance survey found that 68% of organizations cannot reliably distinguish AI agent activity from human activity in their logs. For a compliance function, that is disqualifying. If you cannot separate agent actions from human actions, you cannot certify access, demonstrate segregation of duties, or respond to a data subject access request with confidence. Core Compliance Requirements for AI Agent Access Auditability and Traceability of Agent Actions Every major framework converges on the same demand: show your work. For agents, a login timestamp is not enough. A defensible audit trail captures the full chain of custody for each action: which agent acted, which human or process delegated the authority, which tool or API was invoked, which data was accessed, and what the outcome was. Gartner’s 2026 Market Guide for what it calls “guardian agents” describes exactly this pattern of recording agent-to-tool-to-target chains for compliance reporting and incident response. Data Protection and Privacy Obligations Agents must operate inside the same data protection perimeter as everything else. That means Data Loss Prevention (DLP) controls apply to agent outputs, not just human uploads. It means an agent’s access to personal data needs a lawful basis, documented before deployment, not reverse-engineered after. And it means retention rules follow the data into whatever context window, vector store, or scratchpad the agent moves it into. Separation of Duties in Autonomous Systems Separation of duties exists so that no single actor can both commit and conceal an error or a fraud. A single agent granted permissions across procurement, approval, and payment reconstitutes exactly the toxic combination SOX controls were designed to prevent, except now it executes at machine speed. The control translates directly: no agent should hold permission sets that a human in the same process would be prohibited from combining, and multi-agent workflows need the same conflict analysis as human role assignments. Consent, Purpose Limitation, and Data Minimization Purpose limitation is the principle that agents most naturally violate. An agent given broad access “to be helpful” will use data collected for one purpose to accomplish another, because nothing in its architecture knows the difference. Compliance-ready agent access means scoping data access to the declared purpose of the task and enforcing that scope technically rather than hoping the system prompt holds. Insider Note: In practice, the purpose limitation failures we see are rarely dramatic. They look like a support agent enriching a ticket with data pulled from the sales
When researchers found that Microsoft 365 Copilot could be tricked into leaking corporate data from a single email, the flaw got a clean public identifier: CVE-2025-32711, severity 9.3. When a bug hunter coaxed ChatGPT into producing valid Windows product keys by framing the request as a guessing game, it got nothing. Both were prompt injections. Only one is trackable. That Vulnerability Tracking Gap in AI Security, and what it costs defenders, is the subject of this article. What Is a CVE and Why Does It Matter for Software Security? A CVE (Common Vulnerabilities and Exposures) is a unique public identifier for a specific software flaw. It gives the whole industry one name for one bug, so a researcher in Berlin and an analyst in Bahrain know they mean the same thing. The Role of MITRE’s CVE Program in Traditional Vulnerability Management The CVE program is run by the MITRE Corporation, a US nonprofit. Since 1999 it has assigned hundreds of thousands of IDs, each tied to a discrete, reproducible defect in a defined product and version. A CVE is the connective tissue of coordinated disclosure: a researcher reports the flaw, the vendor patches it, the ID is published, and defenders map it to their own assets. Without that shared label, the same bug ends up with three names and no clear owner. The National Vulnerability Database (NVD) and CVSS Scoring The National Vulnerability Database, maintained by NIST, enriches each CVE with a CVSS (Common Vulnerability Scoring System) score from 0 to 10. That lets teams triage: a 9.3 jumps the queue, a 4.0 waits. Why Prompt Injection Breaks the Traditional CVE Model The CVE model assumes a bug lives in code, sits in a version, and can be fixed. Prompt injection violates all three. Prompt Injection as a Class of Attack, Not a Discrete Bug Prompt injection smuggles instructions into the data an LLM reads, so the model follows the attacker rather than the user. OWASP ranks it as LLM01, the top entry in its 2025 Top 10 for LLM Applications. It is a property of how language models work, not one line of faulty code, so you cannot file a CVE against it. A SQL injection either works or it does not. A prompt injection might succeed nine times in ten, fail on the eleventh, then stop working after a silent model update, which makes the “reproducible” part of reporting genuinely hard. Model Versioning vs. Software Versioning Software has clean version numbers. A weight update to a hosted model can ship silently, with no version a researcher can cite. Two calls to “gpt-4o” a week apart may not behave the same way, and there is no changelog to point at. Why “Patching” an LLM Differs From Patching Code Patching code closes a specific hole. A developer rewrites the faulty line, ships the diff, and the exploit path is gone for good. That clean, binary, auditable loop is the entire premise on which the CVE system rests. “Patching” a model offers none of it. There is no single line to fix, because the behavior the attacker abused is the same behavior that makes the model useful: it reads text and follows instructions. A vendor’s only levers, retraining, hardening the system prompt, or wrapping the model in input and output guardrails, all lower the odds of a successful attack rather than removing the possibility. The fix reduces the success rate from 80 percent to 5 percent and marks it as remediated. The hole is narrower, not closed. The recent record shows how thin that margin is. EchoLeak got past Microsoft’s dedicated cross-prompt-injection classifier by hiding its exfiltration channel in reference-style Markdown that the filter did not recognize, and the AgentFlayer exploit slipped through OpenAI’s URL safety check by routing stolen data through trusted Azure Blob Storage links. Each guardrail worked against the obvious version of the attack and fell to a rephrasing. There is a tuning tax on top of that: crank the filters too tight and the model starts refusing legitimate work, so vendors settle for a balance point rather than elimination. The practical takeaway is to treat “we’ve addressed this” as risk reduction, not closure. SOC 2, ISO 27001 and HIPAA done for you. Fixed fee, 100% audit pass rate. Audit-ready in 6 weeks. Not 6 months. Schedule A Free ASSESSMENT The Current State of AI Vulnerability Tracking Several frameworks exist. None is a true registry of individual, citable prompt injection vulnerabilities. OWASP LLM Top 10 and the LLM01 Classification The OWASP GenAI Security Project’s LLM01:2025 entry is the most cited reference point. It is a category, not a catalog: it does not enumerate specific incidents with IDs. MITRE ATLAS for Adversarial AI Threats MITRE ATLAS is an ATT&CK-style knowledge base of adversarial tactics against AI systems, documenting 16 tactics and more than 80 techniques with real-world case studies as of late 2025. It maps how attacks work, but is not a per-vulnerability ledger with scores. AVID (AI Vulnerability Database) and Its Limitations AVID, run by a nonprofit, is the closest thing to a dedicated AI vulnerability database, cataloging failure modes with reproducible evidence. But it leans on community submissions, skews toward bias and broader failure modes, and notes that the definition of an “AI vulnerability” is itself still a working one. Vendor-Specific Disclosures vs. Industry-Wide Registries Disclosure happens vendor by vendor. OpenAI patched the Windows-key jailbreak server-side; Microsoft fixed EchoLeak and issued a CVE. There is no common venue where these land side by side. The Consequences of No Shared Threat Registry for Prompt Injection Fragmented Disclosure Across AI Vendors Each lab discloses on its own terms, on its own blog, if at all. A defender protecting a multi-model stack has to monitor a dozen channels and hope nothing slips by. Duplicate Discovery and Wasted Research Effort Researchers rediscover the same attack repeatedly. The guessing-game jailbreak, the “dead grandma” trick, and other framing attacks are variations on one theme nobody numbered. No Standardized Severity Scoring for

Most security certifications were built for software that follows rules. AI agents do not. They consume data, draw conclusions, call tools, and take action, increasingly without a human in the loop. That gap is what AIUC-1 was created to close: it is the first auditable security standard built specifically for AI agents, and a few enterprise buyers have started asking vendors for it by name. This guide covers what AIUC-1 actually tests, the six risk domains it audits, how the certification process works, what it costs, how long it lasts, and how it aligns with SOC 2, ISO 42001, ISO 27001, and the NIST AI Risk Management Framework. It also covers the structural questions worth asking before you treat an AIUC-1 report as proof of anything. What Is AIUC-1 Certification? AIUC-1 is a certifiable standard for AI agents created by the Artificial Intelligence Underwriting Company (AIUC), a San Francisco-based, venture-backed startup founded by people with experience at organizations including Anthropic. The standard was developed with input from Orrick, Stanford, the Cloud Security Alliance, MIT, and MITRE, and launched in mid-2025. The framework comprises 51 requirements and 130 controls, organized across six risk pillars. It evaluates whether an organization has implemented and tested the technical guardrails, operational practices, and legal policies needed to reduce the risk of unsafe, unreliable, or unauthorized AI behavior. Certification applies to a specific AI system or product, not to the organization as a whole. An AIUC-1 certificate, audit report, and badge tell enterprise buyers that an agent has been independently tested against agent-specific risks. People describe AIUC-1 as the “SOC 2 for AI agents,” and the analogy holds in spirit. The difference is what it looks at. SOC 2 examines a service organization’s general controls. AIUC-1 examines how an agent behaves under pressure: when someone tries to jailbreak it, when it is asked to do something outside its scope, when it has access to data it should not expose. Worth Knowing: About AIUC-1 AIUC-1 does not define what counts as an “AI agent.” The vendor decides which system to certify and what falls in scope. That makes scope the single most important thing to check on any certificate, because a narrowly scoped audit may not cover the agent you actually use. Why AIUC-1 Certification Matters for Enterprise AI Adoption The business case rests on a simple problem: enterprises cannot reliably assess the security of their AI vendors, and the failures are expensive. According to EY research on responsible AI, 64% of companies with over $1 billion in revenue have already lost more than $1 million to AI-related failures. That gap shows up directly in sales cycles. When security, legal, and procurement teams evaluate an AI vendor, they ask about hallucinations, prompt injection defenses, and what happens when an agent makes an unauthorized call. SOC 2 and ISO 27001 do not answer those questions. AIUC-1 gives buyers a structured, third-party-tested answer, which is why holding the certificate can move a stalled procurement review forward. The certification also produces real engineering outcomes, not just a badge. AIUC has reported cases where a customer service agent’s hallucination rate dropped from 11% to under 2% after strengthening its groundedness filter, and another where inappropriate-tone outputs fell from 9% to under 2% through better defensive prompting and output moderation. One company found and patched a PII exposure vulnerability during the certification process itself. The Six Core Risk Domains Covered by AIUC-1 AIUC-1’s 51 requirements are grouped into six domains. Each targets a category of risk that traditional security frameworks were not designed to handle. Data and Privacy Covers how customer data is used, retained, and protected. Requirements address input and output data policies, limits on what data the agent can access, protection of IP and trade secrets, prevention of cross-customer data exposure, and prevention of PII leakage. This is where the standard forces clarity on whether customer data trains the model and how long it is kept. Security The adversarial-resistance domain. It covers third-party testing of adversarial robustness, detection and real-time filtering of malicious inputs, prevention of prompt injection and unauthorized agent actions, enforcement of user access privileges, and protection of the deployment environment. This is the heart of what separates an agent audit from a general security audit. Safety Focuses on preventing harmful and out-of-scope outputs. Requirements include defining an AI risk taxonomy, conducting pre-deployment testing, preventing harmful and customer-defined high-risk outputs, and flagging high-risk outputs for human review. Safety is partly judgment-based, which means documentation alone can sometimes satisfy a requirement, so the testing behind it deserves scrutiny. Reliability Targets the failure modes that erode trust in production: hallucinations and tool misuse. Controls cover hallucination prevention and restrictions on which tools an agent can call and when. For a customer-facing agent, this is the domain that keeps it from inventing a refund policy or triggering the wrong workflow. Accountability Covers what happens when things go wrong. Requirements include AI failure response plans, vendor due diligence, and clear AI disclosure so users know when they are interacting with an agent. With human workers, accountability is built into org charts and chains of command. Agents need an equivalent, and this domain supplies it. Society The broadest domain, focused on preventing misuse with wider consequences: AI-enabled cyber attacks and CBRN (chemical, biological, radiological, nuclear) misuse. Most enterprise agents will touch only a few of these controls, but they matter for higher-capability systems. Insider Note: Of the 130 total controls, roughly 65 are mandatory, and 65 are optional. A straightforward agent typically needs to meet around 40 controls. A complex, multi-modal agent gets closer to 65. The scoping exercise determines which apply, so two AIUC-1 certificates can represent very different amounts of work. Ready to Earn Your AIUC-1 Certification? Accelerate Your AI Certification Journey Talk to an Expert Who Needs AIUC-1 Certification? AIUC-1 is built for any company developing or deploying agentic AI that sells into enterprises. The strongest fit is an organization whose product uses AI agents in customer-facing operations, handles