In March 2026, a regional conflict in the Middle East did something that stress tests and tabletop exercises rarely manage to do: it took down cloud infrastructure across multiple availability zones at the same time, in the same region, without warning.
AWS data centers in the UAE and Bahrain were impacted. Banking apps went offline. Payments failed. Delivery platforms stopped. And a significant portion of the affected organizations had done everything “right” by conventional standards — multi-AZ deployments, redundancy within the region, documented continuity plans.
It wasn’t enough.
This article breaks down what happened, what it revealed about how most organizations think about availability, and what a more resilient architecture actually looks like. If your systems run on cloud infrastructure — in any region — this case is worth understanding closely.

What Happened: The March 2026 Incident
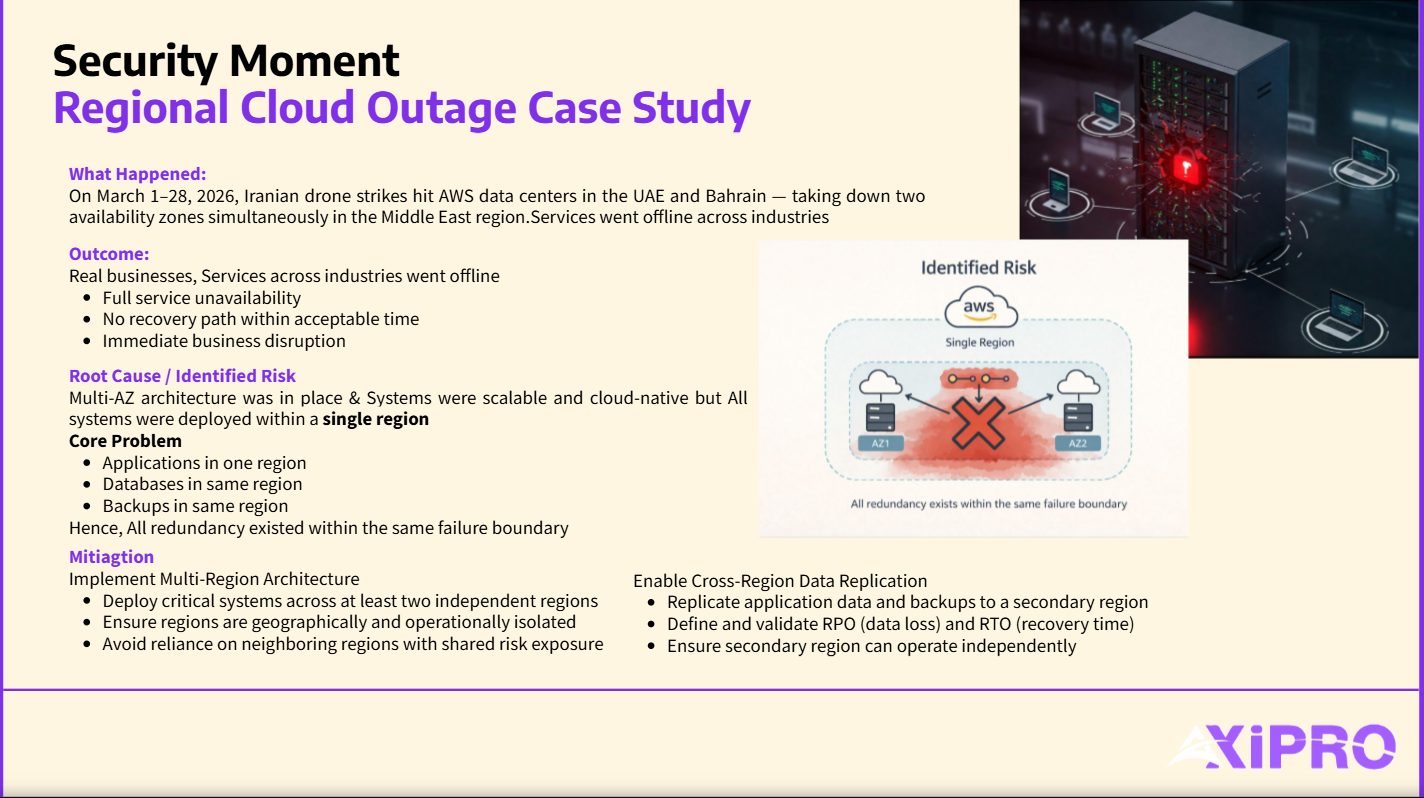
Regional conflict in the Middle East caused physical and infrastructural disruption to AWS facilities across the UAE and Bahrain. Based on publicly reported information, the incident involved power outages affecting data center operations, physical damage to infrastructure facilities, connectivity loss across affected environments, and service degradation spanning multiple availability zones within the same region — simultaneously.
That last point is the one that matters most. AWS designs its availability zones to be isolated from one another — separate power, cooling, and networking — so that a failure in one zone doesn’t cascade into another. Under normal failure conditions, that isolation holds. But this wasn’t a normal failure condition. It was a regional-scale disruption. The “rooms” were fine. The “building” was the problem.
“Availability zones are designed to handle localized failures, not regional ones. This incident sits firmly in the second category.”
The result was that organizations with multi-AZ architectures — which many rightly considered robust — still went down. There was no in-region fallback left to use.
Business Impact: What Actually Went Offline
The impact was not subtle. Banking platforms experienced downtime that prevented customers from accessing accounts or completing transactions. Payment processors were unable to process transactions. Mobility and delivery platforms halted operations entirely. Customer-facing applications became unavailable across the board.
This wasn’t degraded performance or slower load times. It was a full loss of availability for any system that lived entirely within the affected region. The AWS Well-Architected Framework acknowledges that regional failures, while rare, are a defined risk category — and designing for them requires a fundamentally different approach than designing for AZ failures.
Organizations with multi-region architectures kept operating. Everything else stopped. That single architectural decision — single-region versus multi-region — was the difference between availability and a complete outage.
What Risks Actually Materialised
This incident didn’t create new risks. It exposed ones that were already there, quietly embedded in architectural choices and compliance assumptions that had never been stress-tested at this scale.
Regional Single Point of Failure
The most common pattern among affected organizations: applications, databases, and backups all deployed within a single region. When that region became unavailable, there was no secondary environment to take over. No warm standby, no traffic rerouting, no automated failover. Just downtime.
This is the architectural equivalent of backing up your data to a drive sitting next to your laptop. It works until it doesn’t.
The Limits of Availability Zone Redundancy
Availability zones are a powerful tool — but they’re a tool designed for a specific class of failure, and understanding that class matters. Think of an availability zone as a separate floor in a building. If one floor has a problem, you move to another floor. But if the entire building loses power — or becomes inaccessible — floor redundancy doesn’t help. You needed another building entirely. That’s what a region is. And this incident took down the building.
Pro tip: When mapping your architecture against a business continuity plan, explicitly define your regional failure scenario. “What happens if this entire region becomes inaccessible for 24 hours?” is a question that exposes gaps that AZ-level planning will never catch.
Infrastructure-Level Disruption Is Not Solvable at the Application Layer
Power outages. Connectivity loss. Physical damage. These are not conditions that clever application architecture can work around if your infrastructure is entirely contained within the affected geography. No amount of microservices design, caching strategy, or auto-scaling helps when there’s no power reaching the data center.
This is an important framing shift for engineering teams who own availability: some failure modes require infrastructure-layer responses, not code-layer ones.
The Compliance Gap: Controls on Paper vs. Controls in Practice
Perhaps the most uncomfortable implication of this incident. In many environments — particularly those undergoing ISO/IEC 27001:2022 certification or SOC 2 audits — availability controls are documented but don’t reflect the actual system architecture. Redundancy is listed as a control. It’s just redundancy within a single region, which, as this event demonstrated, is insufficient for regional-scale disruptions. The control passes an audit. It fails a real incident.
This is the exact gap that compliance frameworks are designed to close — and that audit processes sometimes fail to catch.
Cloud Hosting and SOC 2 Compliance Requirements
Choosing AWS or Azure doesn’t hand you a SOC 2 compliance. It hands you a shared responsibility model, which means your provider secures the physical infrastructure and you secure everything running on top of it — including whether your architecture can actually deliver on your availability commitments.
Auditors know this distinction well. When they evaluate your Availability criteria, they’re looking at your controls, not your provider’s SOC 2 report.
What that means in practice: your recovery objectives need to be real numbers tied to a real architecture, not placeholders in a policy document. Your failover plan needs test records behind it. And your cloud provider should appear in your vendor risk register with an annual review of their own audit reports.
A single-region deployment with no tested failover isn’t compliant in any meaningful sense. It’s a documentation exercise waiting to be disproved.
The March 2026 incident made this concrete. Organizations that had documented availability controls but confined their entire infrastructure to one region found those controls counted for nothing when the region went down. The control passed the audit. It failed the incident.
That gap is exactly what a SOC 2 audit is supposed to catch. Sometimes it doesn’t.
What Mitigating Controls Could Have Reduced the Impact
The following aren’t theoretical best practices. They’re the specific capabilities that separated organizations that stayed online from those that didn’t.
Multi-region deployment is the foundational requirement. Deploying systems across independent geographic regions — not just independent availability zones — means a regional disruption in one location doesn’t take everything down. Google Cloud’s documentation on multi-region architectures provides useful reference material on how this is structured in practice.
Cross-region data replication ensures that when failover happens, the secondary region has current data to work with. Replication lag is a design variable — it can be tuned based on acceptable recovery point objectives. What can’t be tuned is the existence of the replication relationship itself. If it isn’t there before the incident, it can’t help during one.
Automated failover removes the human response time variable from the equation. If traffic rerouting to a secondary region requires manual intervention, you are adding minutes or hours to your outage window during the exact moment when your team is most overwhelmed. Route 53 failover routing, Azure Traffic Manager, and equivalent tools in other clouds exist specifically for this scenario.
Regional outage testing is the practice that most organizations skip. Simulating a full regional failure — not just a single AZ — validates whether recovery strategies actually work, not just whether they exist. The NIST SP 800-34 guide on contingency planning recommends testing at the scenario level, not just the control level.
Dependency resilience is the one that catches teams off guard. If your identity provider, monitoring stack, or secrets management system lives in the same region as your primary workload, your failover may not actually work — because the systems your application depends on to function are also offline.
Insider note: A common failure in multi-region DR testing is discovering that the authentication service doesn’t fail over cleanly, even when the application does. Audit your dependency chain before you test — not during.
Compliance Perspective: What the Frameworks Actually Require
This incident maps cleanly onto requirements that many organizations are already accountable for.
ISO/IEC 27001:2022 addresses this directly across several controls. A.8.14 covers redundancy of information processing facilities — and the intent is effective redundancy, not documented redundancy. A.8.13 covers backup, with an expectation that backup data is accessible when primary systems are not. A.5.30 addresses ICT readiness for business continuity, which includes planning for scenarios beyond localized failure. The standard is explicit that controls must be implemented in a way that is proportionate to the risk — and a single-region deployment for a mission-critical application is a risk the standard expects to be addressed.
Unsure whether your current architecture actually satisfies these controls? An ISO 27001 gap analysis is usually the fastest way to find out, and an internal audit against your documented controls will surface the delta between what’s on paper and what’s in production.
SOC 2 Availability Criteria requires that systems are available in line with commitments and expectations. If your service-level commitments assume high availability, and your architecture cannot deliver that when a region goes offline, you have a gap between your commitments and your design. The AICPA’s Trust Services Criteria are clear on this point: availability controls must reflect real-world capability, not aspirational architecture.
The common thread across both frameworks: compliance asks whether controls are effective, not just whether they’re present. This incident is a clear case study in what ineffective-but-documented redundancy looks like under real conditions.
What This Means for Your Organization
The March 2026 incident is not a cautionary tale about a distant edge case. It’s a practical reference point for evaluating your own architecture — right now, before you need it.
The questions worth asking are direct ones. Can your systems operate if an entire cloud region becomes unavailable — not for five minutes, but for hours? Does your failover extend beyond a single region, or does it just move traffic between availability zones? Have you tested a full regional failure scenario, or only component-level failures? Do your compliance controls reflect actual system architecture, or how it was originally designed two years ago?
If the answer to any of those is uncertain, that uncertainty is the finding.
NIST‘s Cybersecurity Framework is also worth revisiting in this context — specifically the “Recover” function, which provides a structured way to think about resilience planning at the organizational level, not just the infrastructure level.
Conclusion
The March 2026 incident made one thing concrete: availability is not defined by the presence of redundancy within a region — it’s defined by the ability to operate beyond it.
Multi-AZ architecture is good design. It protects against the failures it’s designed to protect against. But it was never intended to be a substitute for multi-region resilience, and organizations that treated it as one found out the hard way. For most organizations, closing this gap doesn’t require rebuilding from scratch. It requires an honest assessment of where your architecture actually stands versus where you assumed it did.
Axipro works with scaling software companies to assess availability architecture, close compliance gaps, and ensure that continuity controls hold up under real-world conditions — not just audit conditions. If the questions raised in this article surfaced something worth investigating in your own environment, reach out to our team to schedule a technical review. Or if you’d prefer to start with a self-assessment, learn more about how we approach availability and compliance readiness.